
- 1有道词典Android客户端包体积优化之路_resource.arsc优化
- 2uni-app 编译报错 unexpected character
- 3数据质量报告的监控与预警
- 4ChatGPT发展与技术基础_从chatgpt推出
- 5加密水龙头列表新版_sol水龙头
- 6OpenFoam中的Simple系列算法_openfoam 中simple.consistent
- 7硬件结构图_紫光同创PGL22G开发平台试用连载(1)——开发板硬件软件初步评估篇...
- 8Robust Real-time UAV Replanning Using Guided Gradient-based Optimization and Topological Paths_fast planner论文
- 9学习TypeScript21(webpack构建ts+vue3项目)_ts+swc
- 10MATLAB 使用 10 行 代码尝试深度学习_matlab的deep learning toolbox model for alexnet net
港大开源图基础大模型OpenGraph: 强泛化能力,前向传播预测全新数据
赞
踩
OpenGraph 投稿向 凹非寺
量子位 | 公众号 QbitAI
图学习领域的数据饥荒问题,又有能缓解的新花活了!
OpenGraph,一个基于图的基础模型,专门用于在多种图数据集上进行零样本预测。
背后是港大数据智能实验室的主任Chao Huang团队,他们还针对图模型提出了提示调整技术,以提高模型对新任务的适应性。
目前,这项工作已经挂上了GitHub。
据介绍,这项工作主要深入探讨增强图模型泛化能力的策略(特别是在训练和测试数据存在显著差异时)。
而OpenGraph旨在通过学习通用的图结构模式,并仅通过前向传播进行预测,实现对全新数据的零样本预测。
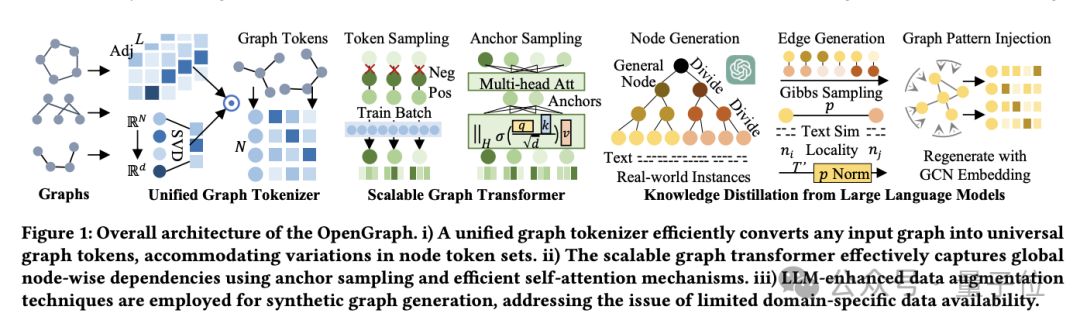
为了实现目标,团队解决了以下3点挑战:
数据集间的token差异:不同图数据集常有不同的图token集,我们需要模型能够跨数据集进行预测。
节点关系建模:在构建通用图模型时,有效地建模节点关系至关重要,这关系到模型的扩展性和效率。
数据稀缺:面对数据获取的难题,我们通过大型语言模型进行数据增强,以模拟复杂的图结构关系,提升模型训练质量。
通过一系列创新方法,如拓扑感知的图Tokenizer和基于锚点的图Transformer,OpenGraph有效应对上述挑战,在多个数据集上的测试结果证明了模型的出色泛化能力。

OpenGraph模型
OpenGraph模型架构主要由3个核心部分组成:
1)统一图Tokenizer;
2)可扩展的图Transformer;
3)基于大语言模型的知识蒸馏技术。
首先来说说统一图Tokenizer。
为了适应不同数据集的节点和边的差异,团队开发了统一图Tokenizer,它将图数据标准化为token序列。
这一过程包括高阶邻接矩阵平滑化和拓扑感知映射。
高阶邻接矩阵平滑化即利用邻接矩阵的高阶幂来解决连接稀疏的问题,而拓扑感知映射则是将邻接矩阵转换为节点序列,并使用快速奇异值分解(SVD)最小化信息损失,保留更多的图结构信息。
其次是可扩展的图Transformer。
在token化后,OpenGraph使用Transformer架构模拟节点间的依赖,主要采用以下技术优化模型性能和效率:
一来是token序列采样,通过采样技术减少模型需要处理的关系数量,从而降低训练的时间和空间复杂度。
二来是锚点采样的自注意力机制。此方法进一步降低计算复杂度,通过分阶段学习节点间的信息传递,有效提高模型的训练效率和稳定性。
最后是大语言模型知识蒸馏。
为了应对培训通用图模型时面临的数据隐私和种类多样性问题,团队从大语言模型(LLM)的知识和理解能力中获得灵感,使用LLM生成各种图结构数据。
这一数据增强机制通过模拟真实世界图的特征,有效提升了数据的质量和实用性。
团队还首先生成适应特定应用的节点集,每个节点拥有文本描述以便生成边。
在面对如电子商务平台这种大规模节点集时,研究人员通过将节点细分为更具体的子类别来处理。
例如,从“电子产品”细化到具体的“移动电话”“笔记本电脑”等,此过程反复进行,直到节点精细到接近真实实例。
提示树算法则按树状结构将节点细分,并生成更细致的实体。
从一般的类别如“产品”开始,逐步细化到具体的子类别,最终形成节点树。
至于边的生成,利用吉布斯采样,研究人员基于已生成的节点集来形成边。
为了减少计算负担,我们不直接通过LLM遍历所有可能的边,而是先利用LLM计算节点间的文本相似度,再通过简单的算法判断节点关系。
在此基础上,团队引入了几种技术调整:
动态概率标准化:通过动态调整,将相似度映射到更适合采样的概率范围内。
节点局部性:引入局部性概念,只在节点的局部子集间建立连接,模拟现实世界中的网络局部性。
图拓扑模式注入:使用图卷积网络修正节点表示,以更好地适应图结构特征,减少分布偏差。
以上步骤确保了生成的图数据不仅丰富多样,而且贴近现实世界的连接模式和结构特性。
实验验证与性能分析
需要注意,该实验专注于使用仅由LLM生成的数据集训练OpenGraph模型,并在多样化的真实场景数据集上进行测试,涵盖节点分类和链接预测任务。
实验设计如下:
零样本设置。
为了评估OpenGraph在未见过的数据上的表现,我们在生成的训练集上训练模型,然后在完全不同的真实测试集上进行评估。确保了训练和测试数据在节点、边和特征上均无重合。
少样本设置。
考虑到许多方法难以有效执行零样本预测,我们引入少样本设置,基线模型在预训练数据上预训练后,采用k-shot样本进行微调。
在2个任务和8个测试集上的结果显示,OpenGraph在零样本预测中显著优于现有方法。
此外,现有预训练模型在跨数据集任务中的表现有时不如从头训练的模型。
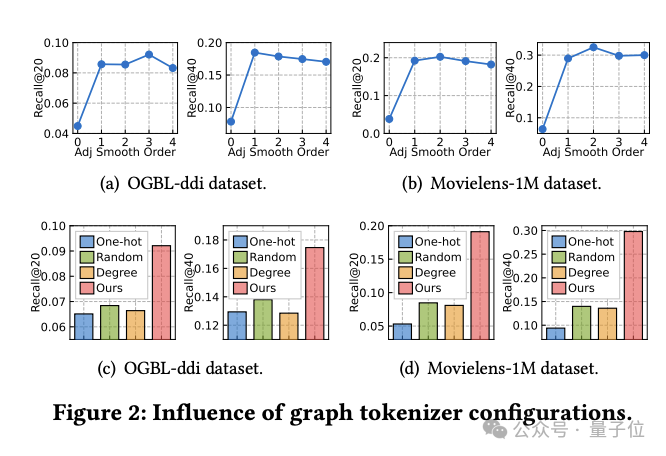
图Tokenizer设计影响研究
同时,团队探索了图Tokenizer设计如何影响模型性能。
首先,通过实验发现,不进行邻接矩阵平滑(平滑阶数为0)会显著降低性能,说明平滑处理的必要性。
然后,研究人员尝试了几种简单的拓扑感知替代方案:跨数据集的独热编码ID、随机映射和基于节点度数的表示。
实验结果显示,这些替代方案性能均不理想。
具体来说,跨数据集的ID表示效果最差,基于度数的表示也表现不佳,而随机映射虽稍好,但与优化的拓扑感知映射相比,性能差距明显。
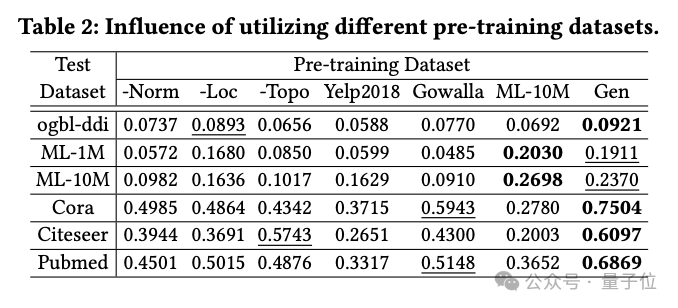
数据生成技术的影响
团队调查了不同预训练数据集对OpenGraph性能的影响,包括使用基于LLM的知识蒸馏方法生成的数据集,以及几个真实数据集。
实验中比较的预训练数据集包括从团队生成方法中移除某项技术后的数据集、2个与测试数据集无关的真实数据集(Yelp2018和Gowalla)、1个与测试数据集类似的真实数据集(ML-10M)。
实验结果显示,生成数据集在所有测试集上均展示了良好性能;三种生成技术的移除都显著影响了性能,验证了这些技术的有效性。
使用与测试集无关的真实数据集(如Yelp和Gowalla)训练时,性能有时候会下降,这可能是由于不同数据集之间的分布差异。
ML-10M数据集在与之类似的测试数据集(如ML-1M和ML-10M)上取得了最佳性能,突显了训练和测试数据集相似性的重要性。
Transformer采样技术的研究
在这部分实验中,研究团队探讨了图Transformer模块中使用的两种采样技术:
token序列采样(Seq)和锚点采样(Anc)。
他们对这两种采样方法进行了详细的消融实验,以评估它们对模型性能的具体影响。
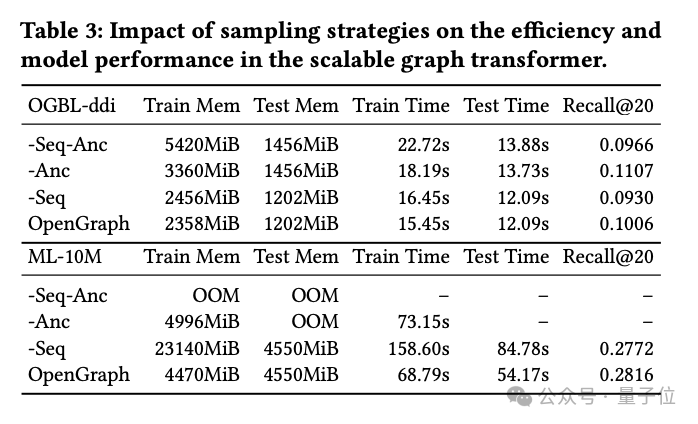
实验结果表明,无论是token序列采样还是锚点采样,两者都能在训练和测试阶段有效地减少模型的空间和时间复杂度。这对于处理大规模图数据尤为重要,可以显著提高效率。
从性能的角度分析,token序列采样对模型的整体性能产生了正面影响。这种采样策略通过选取关键的token来优化图的表示,从而提高了模型处理复杂图结构的能力。
相比之下,在ddi数据集上的实验显示,锚点采样可能对模型性能产生负面影响。锚点采样通过选择特定的节点作为锚点来简化图结构,但这种方法可能会忽略一些关键的图结构信息,从而影响模型的准确性。
综上所述,虽然这两种采样技术都有其优势,但在实际应用中需要根据具体的数据集和任务需求仔细选择合适的采样策略。
研究结论
本研究旨在开发一个高适应性框架,该框架能够精确地识别和解析各种图结构的复杂拓扑模式。
研究人员的目标是通过充分发挥所提出模型的能力,显著增强模型在零样本图学习任务中的泛化能力,包括多种下游应用。
模型是在可扩展的图Transformer架构和LLM增强的数据增强机制的支持下构建的,以提升OpenGraph的效率和健壮性。
通过在多个标准数据集上进行的广泛测试,团队证明了模型的出色泛化性能。
据了解,作为对图基础模型构建的初步尝试,未来,团队工作将着重于增加框架的自动化能力,包括自动识别噪声连接和进行反事实学习。
同时,团队计划学习和提取各种图结构的通用且可迁移的模式,进一步推动模型的应用范围和效果。
参考链接:
[1]论文:
https://arxiv.org/pdf/2403.01121.pdf
[2]源码库:
https://github.com/HKUDS/OpenGraph

