
- 1malloc最多能分配多大的内存空间?_malloc的上限
- 2Android 异常解决方法汇总_"throwing new exception 'no \"i\" field \"speed\"
- 3”Could not find tag for codec none in stream #0, codec not currently supported in container”的解决方法
- 4数学基础task05 高等数学之中值定理_平均值定理可以取端点吗
- 5java基于opencv图片灰度处理小工具_在java中使用opencv处理网络图片
- 6关于嵌入式 Qt 最全最棒的教程(万字干货)_嵌入式qt
- 7VsCode中Vue代码格式插件,Vetur、ESLint 、Prettier - Code formatter的介绍使用及相关配置_vetur插件
- 8【微服务】Eureka(服务注册,服务发现)
- 9SpringMVC基础Controller
- 10Unity2020 il2cpp 代码多的情况下,直接打包出错,使用obb模式或导出到AndroidStudio工程再打apk没问题_unity android obb
详解多模态 AI
赞
踩
2022 年 11 月,OpenAI 推出了 ChatGPT。它只用了几天时间就以其前所未有的能力席卷了世界。生成式人工智能革命已经开始,每个人都在问同一个问题:下一步是什么?
当时,ChatGPT 和许多其他由大型语言模型 (LLM) 提供支持的生成式 AI 工具旨在处理来自用户的文本输入并生成文本输出。换句话说,它们被认为是单模态的人工智能工具。
今天,如果我们要回答一个问题,下一步是什么?最好的答案可能是多模态学习。这是正在进行的人工智能革命中最有希望的趋势之一。多模态生成式 AI 模型能够组合各种类型的输入,并创建可能还包括多种类型输出的输出。
在本指南中,我们将带您了解多模态 AI 的概念。我们将了解多模态 AI 的定义、其核心概念、底层技术和应用,以及如何在现实世界中实现它们。准备好实现多式联运了吗?让我们开始吧!
了解多模态 AI
虽然大多数先进的生成式人工智能工具仍然无法像人类一样思考,但它们正在提供突破性的结果,使我们更接近通用人工智能(AGI)的门槛。该术语指的是一个假设的人工智能系统,它可以像人类一样理解、学习和应用知识来完成各种任务。
在关于如何实现 AGI 的辩论中,我们需要解决的一个核心问题是人类如何学习。这就引出了人类大脑是如何工作的。长话短说,我们的大脑依靠我们的五种感官从周围环境中收集各种信息。然后,这些信息被存储在我们的记忆中,经过处理以学习新的见解,并用于做出决策。
第一个现代生成式 AI 模型,如 ChatGPT,被认为是单模态的;也就是说,他们只能将一种类型的数据作为输入并生成相同类型的输出。特别是,这些模型中的大多数被设计为处理文本提示并生成文本响应。
这是有道理的,因为这些模型需要大量的数据来训练,而文本不仅是一种可以轻松存储和处理的数据类型,而且也很容易获得。ChatGPT 等工具的大部分训练数据都来自互联网上的不同来源也就不足为奇了。
然而,阅读只是人类学习新事物的各种方式之一,而且对于许多任务来说,并不是最有效的。
多模态学习是人工智能的一个子领域,它试图通过使用大量文本以及其他数据类型(也称为感官数据,如图像、视频或录音)来训练机器来增强机器的学习能力。这使得模型能够学习文本描述与其相关图像、视频或音频之间的新模式和相关性。
多模态学习正在为智能系统开启新的可能性。训练过程中多种数据类型的组合使多模态 AI 模型适用于接收多种输入类型的模态并生成多种类型的输出。例如,ChatGPT 的基础模型 GPT-4 可以接受图像和文本输入并生成文本输出,以及 OpenAI 最近发布的 Sora 文本到视频模型。
多模态人工智能的核心概念
多模态生成式 AI 模型为最先进的 LLM 增加了新的复杂性。这些模型基于一种称为 Transformer 的神经架构。Transformer 由 Google 研究人员开发,依靠编码器-解码器架构和注意力机制来实现数据的高效处理。
这是一个相当复杂的过程,可能难以理解。如果您想了解有关 LLM 和 Transformer 如何工作的更多详细信息,请自行百度。

多模态 AI 依靠数据融合技术来集成不同的数据类型,并构建对基础数据的更完整、更准确的理解。最终目标是通过结合不同数据模式提供的互补信息来做出更好的预测。
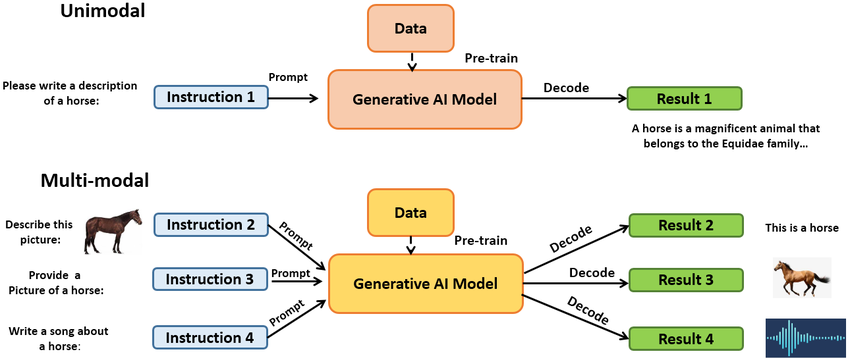
单模态与多模态 AI
可以实施多种数据融合技术来应对多模态挑战。根据融合发生的处理阶段,我们可以将数据融合技术分为三类:
- 早期融合。它涉及将不同的模态编码到模型中以创建通用表示空间。此过程会产生单个模态不变输出,该输出封装了来自所有模态的语义信息。
- 中融合。它涉及在不同的预处理阶段组合模态。这是通过在神经网络中创建专门为数据融合目的而设计的特殊层来实现的。
- 晚期融合。它涉及创建多个模型来处理不同的模态,并将每个模型的输出组合到一个新的算法层中。
没有一种单一的数据融合技术最适合所有类型的场景。相反,所选择的技术将取决于手头的多模式任务。因此,可能需要反复试验才能找到最合适的多模态 AI 管道。
支持多模态 AI 的技术
多模态人工智能是在人工智能的多个子领域积累知识的结果。近年来,人工智能从业者和学者在以多种格式和方式存储和处理数据方面取得了令人瞩目的进展。
在下面,您可以找到推动多模态 AI 热潮的领域列表:
深度学习
深度学习是人工智能的一个子领域,它采用一种称为人工神经网络的算法来处理复杂的任务。当前的生成式人工智能革命是由深度学习模型驱动的,特别是 transformer,这是一种神经架构。
多模态人工智能的未来也将取决于该领域的新进展。特别是,非常需要研究以找到增强变压器功能的新方法,以及新的数据融合技术。
自然语言处理 (NLP)
NLP是人工智能中的一项关键技术,弥合了人类交流和计算机理解之间的差距。它是一个多学科领域,使计算机能够解释、分析和生成人类语言,从而实现人与机器之间的无缝交互。
由于与机器通信的主要方式是通过文本,因此 NLP 对于确保生成式 AI 模型(包括多模态模型)的高性能至关重要也就不足为奇了。
计算机视觉
图像分析,也称为计算机视觉,包括一组计算机可以“看到”和理解图像的技术。该领域的进展允许开发多模态 AI 模型,这些模型可以将图像和视频作为输入和输出进行处理。
音频处理
一些最先进的生成式 AI 模型能够将音频文件作为输入和输出进行处理。音频处理的可能性范围从解释语音信息到同声传译和音乐创作。
多模态AI的应用
多模态学习使机器能够获得新的“感官”,从而提高其准确性和解释能力。这些权力为跨部门和行业的无数新应用打开了大门,包括:
增强生成式 AI
大多数第一代生成式 AI 模型都是文本到文本的,能够处理用户的文本提示并提供文本答案。GPT-4 Turbo、Google Gemini 或 DALL-E 等多模态模型带来了新的可能性,可以改善输入和输出端的用户体验。无论是接受多种模式的提示还是生成各种格式的内容,多模式 AI 代理的可能性似乎都是无限的。
自动驾驶汽车
自动驾驶汽车严重依赖多模态人工智能。这些汽车配备了多个传感器,以各种格式处理来自周围环境的信息。多模态学习是这些车辆以有效和高效的方式组合这些来源以实时做出情报决策的关键。
生物医学
来自生物库、电子健康记录、临床成像和医疗传感器的生物医学数据以及基因组数据的可用性不断提高,正在推动医学领域多模态人工智能模型的创建。这些模型能够处理这些以多种方式出现的各种数据源,以帮助我们解开人类健康和疾病的奥秘,并做出明智的临床决策。
地球科学与气候变化
地面传感器、无人机、卫星数据和其他测量技术的快速发展正在提高我们了解地球的能力。多模态人工智能对于准确组合这些信息至关重要,并创建新的应用程序和工具,可以帮助我们完成各种任务,例如温室气体排放监测、极端气候事件预测和精准农业。
实施多模态 AI 解决方案的挑战
多模态人工智能的繁荣为企业、政府和个人带来了无限的可能性。但是,与任何新兴技术一样,在日常运营中实施它们可能具有挑战性。
首先,您需要找到符合您特定需求的用例。从概念到部署的转变并不总是那么容易,特别是如果你缺乏正确理解多模态人工智能背后的技术细节的人。然而,鉴于目前数据素养差距,找到合适的人将模型投入生产可能既困难又昂贵,因为公司愿意支付高额费用来吸引如此有限的人才。
最后,在谈到生成式人工智能时,必须提到可负担性。这些模型,尤其是多模态模型,需要大量的计算资源才能工作,这意味着金钱。因此,在采用任何生成式 AI 解决方案之前,重要的是要估计您要投资的资源。
多模态人工智能的风险
与任何新技术一样,我们必须使用多模态 AI 模型来应对几个潜在的陷阱:
- 缺乏透明度。 算法的不透明性是与生成式人工智能相关的主要问题之一。这也适用于多模态 AI。这些模式通常被标记为“黑匣子”模型,因为它们很复杂,这使得无法监控它们的推理和内部工作原理。
- 多模态 AI 垄断。 鉴于开发、培训和运营多式联运模型所需的大量资源,市场高度集中在拥有必要专业知识和资源的大型科技公司中。幸运的是,越来越多的开源 LLM 正在进入市场,这使得开发人员、AI 研究人员和社会更容易理解和操作 LLM。
- 偏见和歧视。根据用于训练多模态 AI 模型的数据,它们可能包含偏见,可能导致不公平的决定,这些决定往往会加剧歧视,尤其是针对少数群体的歧视。如前所述,透明度对于更好地理解和解决潜在的偏见至关重要。
- 隐私问题。多模态 AI 模型使用来自多个来源和格式的大量数据进行训练。在许多情况下,它可能包含个人数据。这可能会导致与数据隐私和安全相关的问题和风险。
- 道德考虑。 多模态人工智能有时会导致对我们的生活产生严重影响的决定,对我们的基本权利产生重大影响。
- 环境考虑。研究人员和环境监管机构对与训练和操作生成式人工智能模型相关的环境足迹表示担忧。专有多模态人工智能模型的所有者很少发布有关模型消耗的能源和资源的信息,也很少发布相关的环境足迹信息,这对于这些工具的快速采用来说是非常成问题的。
多模态 AI 的未来
多模态人工智能无疑是生成式人工智能革命的下一个前沿领域。多模态学习领域的快速发展正在推动各种目的的新模型和应用程序的创建。我们才刚刚开始这场革命。随着新技术的发展,将越来越多的新模式结合起来,多模态人工智能的范围将扩大。
然而,权力越大,责任越大。多模态人工智能带来了严重的风险和挑战,需要解决这些风险和挑战,以确保公平和可持续的未来。

