
- 1微信小程序触底加载分页_小程序 scroll-view分页
- 2【推荐100个unity插件之12】UGUI的粒子效果(UI粒子)—— Particle Effect For UGUI (UI Particle)_particleeffectforugui
- 3MP算法和OMP算法及其思想_momp算法
- 4vue-cli3.0项目中设置scss全局变量_vue3如何在jis中更改scss变量的全局的值
- 5Unity XLua 协程 Coroutine_attempt to yield from outside a coroutine
- 6以太坊智能合约开发:Solidity 语言快速入门
- 7阿里云centos7安装Nginx_阿里云安装nginx
- 8Stone 3D教程:创建全景图云展览,只需要几分钟
- 9隐蔽通信(Covert Communication)论文阅读总结(以及正在尝试论文复现)
- 10C# Dictionary(字典)的键、值排序
从零开始的深度学习--2_从零开始深度学习
赞
踩
这个博文主要包括了了第一次课程的内容,包括线性回归,softmax与分类模拟,多层感知机。以下内容将从理论知识和代码解释两部分内容来展开。
理论知识
深度学习模型也可以看作是由许多简单函数复合而成的函数。当这些复合的函数足够多时,深度学习模型就可以表达非常复杂的变换
1、线性回归
运用梯度下降方法预测连续变量的
2、softmax用来预测离散变量
分类问题需要得到离散的预测输出,一个简单的办法是将输出值当作预测类别是的置信度,并将值最大的输出所对应的类作为预测输出。
关于输出的话,如果对预测值和实际值不做限制的话,会有两个问题:
a,由于输出层的输出值的范围不确定,可能无限小或者无限大,我们难以直观上判断这些值的意义。
b,由于真实标签是离散值,这些离散值与不确定范围的输出值之间的误差难以衡量。很难找出那个值是最优的。
基于以上两个问题,我们使用softmax运算符(softmax operator)解决。它通过公式处理将输出值变换成值为正且和为1的概率分布,再根据其概率找到最优预测。
损失函数
交叉熵将作为新的损失函数,原来的平方损失估计不再适用,其计算公式为
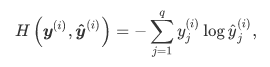
最后我们将准确率(正确次数/总预测次数)作为预测的评价标准。
3多层感知机MLP

多层感知机其实就是在原来的基础上,输入层和输出层之间多插入了一层隐藏层,从而增加了变化。问题来了,如果我们只增加线性变化,那么结果和没有隐藏层是相同的,都能化简成经过一次线性变化。所以在隐藏层我们需要插入一些非线性变化,作为下一层的输入,这个非线性函数就被称为激活函数。
常用的激活函数
ReLU(rectified linear unit)只保留正数元素,并将负数元素清零。
sigmoid函数可以将元素的值变换到0和1之间:
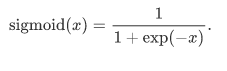
tanh(双曲正切)函数可以将元素的值变换到-1和1之间:
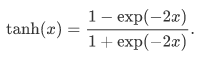
4.序列数据如文本的处理
读入文本;分词;建立字典,将每个词映射到一个唯一的索引(index);将文本从词的序列转换为索引的序列,先统计词频,再去重,筛选出要用的词,添加特殊token(pad补全,bos句子开始,eos句子结束,unk未知词)引入索引,将索引与token对应。方便输入模型;
spcy,NLCK分词工具,可以专门用来分词,可以解决标点,特殊名词等问题。
5.语言模型
目的在于,给定一个语言序列,判断这个序列是否合理,即判断这一序列出现的概率是偶足够大。基于统计模型→n元语法。n元语法通过马尔可夫假设简化模型,马尔科夫假设是指一个词的出现只与前面个词相关。缺点计算存储资源开销太大;数据稀疏。
在训练中我们需要每次随机读取小批量样本和标签。与之前章节的实验数据不同的是,时序数据的一个样本通常包含连续的字符,采用随机采样或者相邻采样来进行,避免大面积重复。
代码实现及释义
view()函数
这个函数会返回具有相同数据但大小不同的新张量。 返回的张量必须有与原张量相同的数据和相同数量的元素,但可以有不同的大小。
x = torch.randn(2, 4)
则会有一随机张量
1.5600 -1.6180 -2.0366 2.7115
0.8415 -1.0103 -0.4793 1.5734
然后下使用view重新构造的话
y = x.view(4,2)
print y
则y将变为
1.5600 -1.6180
-2.0366 2.7115
0.8415 -1.0103
-0.4793 1.5734
.utils.dataset;dataloader
Dataset是一个包装类,用来将数据包装为Dataset类,然后传DataLoader中,我们再使用DataLoader这个类来更加快捷的对数据进行操作。
nn.sequantial
一个有序容器,用来初始化多层网络
nn.init
用于参数初始化, torch.nn.init.normal_指自变量符合正态分布。
初始化方法汇总
nn.MSELoss 均方误差损失函数模块
torch.optim.SGD选用随机梯度下降优化函数
optimier.step() 进行单次优化
torchvision包,它是服务于PyTorch深度学习框架的,主要用来构建计算机视觉模型。torchvision主要由以下几部分构成:
torchvision.datasets: 一些加载数据的函数及常用的数据集接口;
torchvision.models: 包含常用的模型结构(含预训练模型),例如AlexNet、VGG、 ResNet等;
torchvision.transforms: 常用的图片变换,例如裁剪、旋转等;
torchvision.utils: 其他的一些有用的方法。
class torchvision.datasets.FashionMNIST 从网上下载数据集
- 1
- 2
- 3
- 4
- 5
get_fashion_mnist_labels 获取数据标签,转化为文本
show_fashion_mnist 展示数据集
d2l.load_data_fashion_mnist(batch_size)下载训练集数据
re.sub(’[^a-z]+’, ’ ', line.strip().lower())文本每一行去掉空字符,大写全部变为小写,然后用空格替换掉非英文字符。
tokenize(sentences, token=‘word’) 分词函数,token选择分词级别,可以为word或者char
count_corpus 统计词频

