
- 1李阳英语228句口语要素 +校园英语迷你惯用语 +1000句最常用英语口语
- 2linux下的卸载命令_linux 卸载明亮
- 3快速排序算法优化
- 4数据库课设社区卫生服务管理系统_深度解析腾讯自研数据库CynosDB备份与回档...
- 5SQL实例--查询、引索、视图
- 6使用DataX进行数据同步_datax同步数据时源表结构变化而变化
- 7DNS域名解析_配置 dns 解析,将域名指向服务器的公网 ip 地址。
- 8mysql所支持的比较运算符_MySQL比较运算符一览表(带解析)
- 901-嵌入式入门-如何看原理图
- 10【云原生--K8S】 yaml文件部署Mysql数据库(一)_容器mysql得yaml文件指定数据库配置文件
StyleAvatar: Real-time Photo-realistic Portrait Avatar from a Single Video 译文_mead数据集
赞
踩
链接:
https://arxiv.org/abs/2305.00942
摘要
人脸再现方法试图尽可能真实地恢复和再现人脸特征视频。现有的方法面临着质量与可控性的两难境地:与3D方法相比,基于2D GAN的方法实现了更高的图像质量,但在面部属性的细粒度控制方面受到影响。在本文中,我们提出了StyleAvatar,一种使用基于StyleGAN的网络的实时照片真实感人像头像重建方法,它可以生成具有忠实表情控制的高保真人像头像。我们通过引入组合表示和滑动窗口增强方法来扩展StyleGAN的功能,这使得能够更快地收敛并提高翻译泛化能力。具体来说,我们将人像场景分为三个部分进行自适应调整:面部区域、非面部前景区域和背景。此外,我们的网络充分利用了UNet、StyleGAN和time coding的优势来进行视频学习,从而实现高质量的视频生成。此外,还提出了滑动窗口增强方法和预训练策略,分别用于提高翻译泛化能力和训练性能。所提出的网络可以在两个小时内收敛,同时确保高图像质量和仅20毫秒的正向渲染时间。此外,我们还提出了一个实时直播系统,将研究进一步推向应用。结果和实验表明,与现有的人脸重建方法相比,我们的方法在图像质量、全人像视频生成和实时重新动画方面具有优越性。本文的训练和推理代码在https://github.com/LizhenWangT/StyleAvatar。
1. 介绍
真实感人像头像重建和重动画是计算机视觉和计算机图形学中的一个长期存在的主题,具有从视频编辑到混合现实的广泛应用。基于NeRF的肖像头像研究近况[Gafniet al. 2021; Gao et al. 2022; Zheng et al. 2023] 或者存在一些其他3D表示[Grassal et al. 2022a; Zheng et al. 2022a,b;Zielonka et al. 2022] 已经证明可以从单目视频中学习稳定的3D化身。然而,与基于2D GAN的方法相比,大多数3D方法仍然面临分辨率和图像质量的限制。此外,这些方法主要集中在僵硬的面部区域,忽略了长发、身体部位和背景元素。虽然可以直接覆盖背景,但执行得不好的覆盖通常会导致不真实的结果。理想的肖像头像应该优先考虑高保真、快速训练、细粒度控制和实时效率。
从单目视频中学习3D头部头像是近年来的热门话题。早期作品[Gafni et al. 2021; Grassalet al. 2022a; Zheng et al. 2022a] 将NeRF整合到头像中,实现有希望的视图一致性。最近的方法或者旨在实现更好的渲染真实感[Xu et al. 2023b;Zheng et al. 2022b] 或者更快的训练收敛和推理速度[Gao et al. 2022; Xu et al. 2023a; Zielonka et al. 2022] 通过利用更有效的3D表示[Fang et al. 2022; Mülleret al. 2022]. 一般来说,3D方法的核心思想是保持相对固定的特征空间,如拓扑一致的网格或规范空间,以使每个点或体素能够从视频中学习某些局部特征。这种策略导致更大的稳定性,但是由于跟踪不稳定性或其他因素,也会导致平滑的纹理。
另一方面,受益于强大的StyleGAN[Karras et al. 2021, 2019, 2020], 以下作品[Ab-dal et al. 2021; Chen et al. 2022; Deng et al. 2020; Härkönen et al.2020; Shen et al. 2020b; Tewari et al. 2020a,b; Wang et al. 2021b]极大地提高了语义编辑性能。一些方法[Doukas et al. 2021b; Drobyshev et al. 2022; Khakhulinet al. 2022] 可以从单一图像创建头像,而其他人[Sun et al. 2022, 2023; Xiang et al. 2022] 甚至可以用EG3D生成可控的3D人脸[Chan et al. 2022]. 然而,这些基于StyleGAN的方法主要依赖于高度对齐的高清人脸数据集,如FFHQ,它缺乏足够的面部表情变化。此外,它们不能在肖像视频中生成自然的头部运动。
我们提出了StyleAvatar,这是一个使用基于StyleGAN的网络进行照片真实感人像头像重建的实时系统。我们的系统能够在短短三个小时内生成一个高保真的肖像头像。为了解决全照片真实感人像视频重建的挑战,我们将人像场景分成三个部分:面部、可移动的身体部分(肩膀、脖子和头发)和背景。每个部分都有不同的属性:面部部分通过3DMM提供几乎所有的移动信息,而背景通常是静态的。可活动的身体部分可能包含无数不可控的动作,但我们还是可以从面部动作中了解到一些趋势。
为了克服这些挑战,我们提出了StyleAvatar,这是一个使用基于StyleGAN的网络进行照片级逼真肖像头像重建的实时系统。我们的系统可以在短短两个小时内生成一个高保真的人像头像。为了重建完整的人像视频,我们将视频分成三个部分:面部区域、非面部前景区域(肩膀、脖子、头发等)。)和背景。每个部分都有不同的属性:面部区域可以用3DMM来描述;非面部前景区域经常表现出不可控制的运动,但是趋势可以从面部运动中获知;并且背景保持静止。为了更好地表示这三个部分的不同特征,我们使用两个Style-GAN生成器来生成人脸区域和背景的两个静态特征图,并提出一个StyleUNet来从输入的3DMM渲染中生成非人脸前景特征图。为了加快训练和推理速度,我们使用了使用神经纹理[Thies et al. 2019] 在特征组合阶段用于面部区域。此外,我们还引入了滑动窗口增强方法来提高翻译泛化能力,并在一个小的视频数据集上对模型进行预训练,以进一步加快训练速度。最后,使用另一个StyleUNet从组合的特征图生成最终图像。我们的框架旨在通过TensorRT和OpenGL轻松加速,前向渲染时间仅为20毫秒,实现实时现场人像重现。结果和实验表明,我们的方法在图像质量、全人像视频生成和实时再现动画方面优于现有的人脸再现方法。我们的贡献可以总结为:
- 我们引入了一种有效分解人脸区域、非人脸前景区域和背景的合成表示法,这样我们可以根据不同区域的特征进行自适应调整,以提高稳定性和训练速度。
- 我们进一步提出了StyleUNet,它利用了UNet、StyleGAN和时间编码的优点来进行视频学习,从而实现了高质量的视频生成。
- 提出了滑动窗口增强方法和预训练策略,分别提高了翻译泛化能力和训练性能。
2. 相关工作
面部重现的方法。这些方法的目的是在给定另一个人的表现的情况下,生成目标人的照片般逼真的肖像图像(包括脸、头发、脖子甚至肩膀区域),这不同于人脸替换方法[Perov et al. 2020] 或者人脸表现捕捉和动画方法[Li et al. 2012; Weise et al. 2011]. 根据输入数据的不同,人脸再现方法大致可以分为三类:基于多视角系统的方法、基于单视频的方法和基于单图像的方法。基于多视图结构系统,最近的研究[Lombardi et al. 2018, 2019; Ma et al.2021; Raj et al. 2021; Wang et al. 2022a; Wei et al. 2019] 能够生成具有令人印象深刻的细微细节和高度灵活的可控性的面部化身,用于身临其境的度量远程呈现。然而,数据采集的困难限制了它的广泛应用。相反,基于单一图像的方法[Averbuch-Elor et al. 2017;Doukas et al. 2021b; Drobyshev et al. 2022; Geng et al. 2018; Honget al. 2022; Kowalski et al. 2020; Liu et al. 2001; Mallya et al. 2022;Nagano et al. 2018; Olszewski et al. 2017; Siarohin et al. 2019; Vlasicet al. 2005; Yin et al. 2022] 最容易捕捉,并能产生照片般逼真的面部重现效果。然而,当动画化到大的姿态和表情时,形状和细节可能不一致,尤其是对于那些在单个输入图像中没有被很好覆盖的区域,更不用说动态面部细节了。基于单一视频的方法[Doukas et al. 2021a; Garridoet al. 2014; Koujan et al. 2020; Suwajanakorn et al. 2017; Thies et al.2015, 2016] 显示了更稳定的面部重现结果。其中,[Kim et al. 2018] 基于based图像翻译框架,呈现令人印象深刻的完整头部再现和交互式编辑效果。最近的方法[Gafni et al. 2021;Gao et al. 2022;Wang et al. 2021a; Xu et al. 2023a,b; Zielonka et al. 2022] 显示了具有参数控制神经辐射场的最先进的再现结果。其他方法[Cao et al. 2022; Garbin et al.2022; Grassal et al. 2022b; Zheng et al. 2022a,b] 通过利用网格或点云等3D表示,提高了稳定性和纹理质量。然而,现有的基于单视频的面部重现方法在恢复精细细节方面仍然面临挑战,例如头发、雀斑甚至皮肤毛孔。
基于StyleGAN的人脸图像生成和编辑方法。这些方法可以产生高分辨率和照片般逼真的面部图像[Karras et al. 2021, 2019, 2020] 即使在语义编辑操作下[Abdal et al. 2021; Alaluf et al. 2021; Chen et al.2022; Deng et al. 2020; Ghosh et al. 2020; Härkönen et al. 2020;Jang et al. 2021;Ren et al. 2021;Richardson et al. 2021;Shen et al.2020a,b; Shi et al. 2022; Tewari et al. 2020a,b; Tov et al. 2021; Wang et al. 2021b]. 这些工作通过解耦输入潜在空间对StyleGAN生成的图像进行语义修改。此外,戈什等人。[Ghosh et al. 2020] 和肖山等人。[Shoshan et al. 2021] 将StyleGAN潜在空间与语义输入(如3DMM参数)相结合[Blanz and Vetter1999]. 索夫根[Chen et al. 2022] 使用语义分割图来调节图像生成器,并使用额外的3D扫描进行训练来实现3D感知生成。这些方法提供了对生成的照片般逼真的面部图像的形状、姿势、头发和风格的有意义的控制,但是诸如眨眼之类的细粒度表情修改仍然不可用。更重要的是,这些方法严重依赖于预先训练的风格和潜在空间,使得它们很难在编辑过程中保持时间稳定性和细节的一致性。
3. 方法
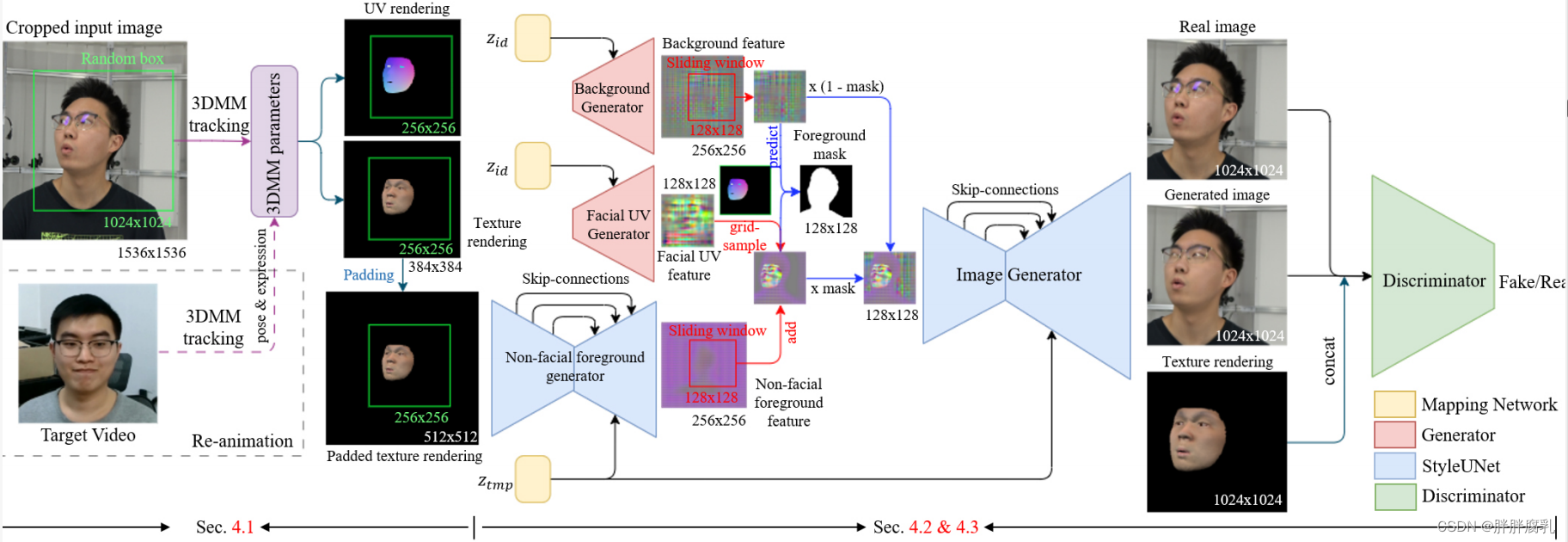
图2:我们的肖像头像重建和再动画流程包括三个主要步骤:3DMM跟踪和渲染,面部区域、非面部前景区域和背景的特征生成,以及组合特征映射的最终图像生成。为了实现这一点,我们使用两个StyleGAN生成器、一个StyleGAN鉴别器和两个styleunet。此外,我们结合了数据增强技术,在输入图像上使用随机框,在生成的特征图上使用滑动窗口,以提高翻译泛化。
如图2所示。 输入单目人像视频,我们首先执行3DMM跟踪(3.1) 使用预测纹理和UV坐标顶点颜色生成合成渲染。接下来,在特征生成阶段(3.2), 我们将人像特征图分成三个部分:由StyleGAN生成器生成的在UV空间中生成的静态人脸特征图;由StyleUNet从输入纹理渲染生成的非面部前景特征图;由另一个StyleGAN生成器生成的静态背景特征图。然后,我们使用神经纹理从UV空间提取人脸特征图,并在特征图的组合过程中引入滑动窗口数据增强,以更好地利用整个视频的信息。最后,使用另一个StyleUNet从组合的特征图生成图像,并引入StyleGAN鉴别器进行对抗学习。注意,在推断阶段仅计算两个StyleUNets,并且可以通过替换来自另一个视频的输入表情和姿态参数来实现重新动画。
3.1 数据处理
我们首先对输入的单目肖像视频进行3DMM跟踪,以生成像素对齐的3DMM渲染,用于后续训练。我们选择使用FaceVerse[Wang et al. 2022b] 因为它丰富的形状和表情基础,我们增加了单独的眼球。具有预测纹理的纹理渲染用于非面部前景特征生成,而具有UV坐标顶点颜色的另一UV渲染用于面部区域的神经纹理。为了在特征组合阶段监督掩模预测的训练,我们使用鲁棒的视频抠图来生成前景掩模[Lin et al. 2021].
对于3DMM系数跟踪算法,我们需要求解形状系数 θ s h a p e \theta_{shape} θshape ,表达式系数 θ e x p r e s s i o n \theta_{expression} θexpression,纹理系数 θ t e x t u r e \theta_{texture} θtexture,平移系数 t t t, 缩放系数 s s s,头部旋转以及眼球和旋转头和两个眼球 R 1 , R 2 , R 3 R_1,R_2,R_3 R1,R2,R3。为了提高效率,我们直接从MediaPipe检测到的人脸关键点坐标
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

