
- 1深入了解AI大模型在语音识别领域的挑战
- 2EncryptUtil加密解密工具类,实测可以,复制粘贴皆可。全套代码加使用案例方法。
- 3为了避免内存攻击,美国国家安全局提倡Rust、C#、Go、Java、Ruby 和 Swift,但将 C 和 C++ 置于一边...
- 4redux的基础学习使用
- 5pytorch,torchvision与python版本对应关系_torch1.10.1对应的torchvision
- 6JavaScript基础(一)_js根据条件显示
- 7多种方式实现Android页面布局的切换_安卓 切换布局文件
- 8主题模型LDA教程:主题数选取 困惑度perplexing_lda困惑度
- 9自然语言处理之准确率、召回率、F1理解_nlp f1
- 10机器学习的入门教学-scikit-learn_scikit-learn教程
Transformer详解
赞
踩
近期Transformer系列模型的出现,增加了CV领域的多样性。但是Transformer这一不同领域的模型对学习者来说需要一个细致的学习过程.下面就是本菜鸟总结学习路线。
Transformer是基于attention机制。而attention机制又在Encoder、Decode中。本篇博客将从Attention->Encoder-Decode->Transformer逐步讲解,一步一步深入,本篇博客也是对自己学习的一个总结,将相关学习内容分享出来与大家共同进步。如有不妥之处还望及时指出。
废话不多说,先上结构。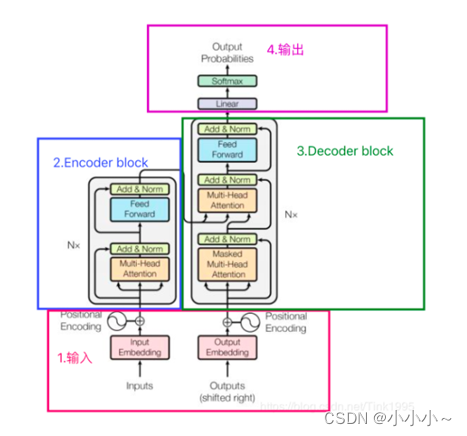
一、输入
(一)、词向量的输入

Transformer输入是一个序列数据,以我爱你为例:Encoder 的 inputs就是"I LOVE YOU" 分词后的词向量。
输入inputs embedding后需要给每个word的词向量添加位置编码positional encoding。
之所以要进行位置迁入,我们可以这样理解。一句话中同一个词,如果词语出现位置不同,意思可能发生翻天覆地的变化,就比如:我欠他100W 和 他欠我100W。这两句话的意思一个地狱一个天堂。可见获取词语出现在句子中的位置信息是一件很重要的事情。但是Transformer 的是完全基于self-Attention地,而self-attention是不能获取词语位置信息的,就算打乱一句话中词语的位置,每个词还是能与其他词之间计算attention值,就相当于是一个功能强大的词袋模型,对结果没有任何影响。所以在我们输入的时候需要给每一个词向量添加位置编码。
(2)positional encoding获取过程:

1.可以通过数据训练学习得到positional encoding,类似于训练学习词向量,goole在之后的bert中的positional encoding便是由训练得到地。
2.《Attention Is All You Need》论文中Transformer使用的是正余弦位置编码。位置编码通过使用不同频率的正弦、余弦函数生成,然后和对应的位置的词向量相加,位置向量维度必须和词向量的维度一致。过程如上图,PE(positional encoding)计算公式如下:

pos表示单词在句子中的绝对位置,pos=0,1,2…,例如:YOU在"I LOVE YOU"中的pos=2;dmodel表示词向量的维度,在这里dmodel=512;2i和2i+1表示奇偶性,i表示词向量中的第几维,例如这里dmodel=512,故i=0,1,2…255。
二、attention机制
(一)、self-attention
假如输入序列是"Thinking Machines",x1,x2就是对应地"Thinking"和"Machines"添加过位置编码之后的词向量,然后词向量通过三个权值矩阵
W
Q
W^Q
WQ、
W
K
W^K
WK、
W
V
W^V
WV ,转变成为计算Attention值所需的Query,Keys,Values向量。

在实际使用中,每一条序列数据都是以矩阵的形式输入地,故可以看到上图中,X矩阵是由"Tinking"和"Machines"词向量组成的矩阵,然后跟过变换得到Q,K,V。假设词向量是512维,X矩阵的维度是(2,512),
W
Q
W^Q
WQ、
W
K
W^K
WK、
W
V
W^V
WV均是(512,64)维,故得到的Query,Keys,Values就都是(2,64)维。
得到Q,K,V之后,接下来就是计算Attention值了。
步骤1: 输入序列中每个单词之间的相关性得分,计算相关性得分可以使用点积法,就是用Q中每一个向量与K中每一个向量计算点积。具体公式如下:
score =
Q
∗
Q*
Q∗
K
T
K^T
KT
步骤2: 对于输入序列中每个单词之间的相关性得分进行归一化,归一化的目的主要是为了训练时梯度能够稳定。具体公式如下:
s
c
o
r
e
=
s
c
o
r
e
x
score =\frac{score}{\sqrt x}
score=x
score,dk就是K的维度,以上面假设为例,dk=64。
步骤3: 通过softmax函数,将每个单词之间的得分向量转换成[0,1]之间的概率分布,同时更加凸显单词之间的关系。经过softmax后,score转换成一个值分布在[0,1]之间的(2,2)α概率分布矩阵
步骤4: 根据每个单词之间的概率分布,然后乘上对应的Values值,α与V进行点积。公式如下:
Z
=
s
o
f
t
m
a
x
(
s
c
o
r
e
)
∗
V
Z=softmax(score)*V
Z=softmax(score)∗V,V的为维度是(2,64),(2,2)x(2,64)最后得到的Z是(2,64)维的矩阵。

(二)、Multi-Head Attention
有了自注意力机制的基础之后,多头注意力机制就迎刃而解了。Multi-Head Attention就是在self-attention的基础上,对于输入的embedding矩阵,self-attention只使用了一组
W
Q
W^Q
WQ、
W
K
W^K
WK、
W
V
W^V
WV
来进行变换得到Query,Keys,Values。而Multi-Head Attention使用多组
W
Q
W^Q
WQ、
W
K
W^K
WK、
W
V
W^V
WV得到多组Query,Keys,Values,然后每组分别计算得到一个Z矩阵,最后将得到的多个Z矩阵进行拼接。
三、Encoder-Decoder
有了多头注意力机制后我能就可以进行Encoder-Decoder的学习了。
Encoder-Decoder框架是编码-解码框架,大部分attention模型都是基于Encoder-Decoder框架进行实现,在NLP中Encoder-Decoder框架主要被用来处理序列-序列问题。也就是输入一个序列,生成一个序列的问题。这两个序列可以分别是任意长度。具体到NLP中的任务比如:
文本摘要,输入一篇文章(序列数据),生成文章的摘要(序列数据)
文本翻译,输入一句或一篇英文(序列数据),生成翻译后的中文(序列数据)
问答系统,输入一个question(序列数据),生成一个answer(序列数据)
(一)、Encoder
从文章最开始的结构图我们可以看出,Encoder-Decoder中在经过Multi-Head Attention后并没有直接进行输出,而是经过了:Add&Normalize。add就是在Z的基础上加了一个残差块X。
至于为什么经过Add&Normalize。可以参考我的另一篇文章:残差块与Normalize的作用
这里强调一下为什么要用到LN。BN是对于相同的维度进行归一化,但是在NLP中输入的都是词向量,一个300维的词向量,单独去分析它的每一维是没有意义地,在每一维上进行归一化也是适合地,因此这里选用的是LN。

Feed-Forward Networks
全连接层公式如下:
F
F
N
(
x
)
=
m
a
x
(
0
,
x
∗
W
1
+
b
1
)
∗
W
2
+
b
2
FFN(x) =max(0,x*W_1+b_1)*W_2+b_2
FFN(x)=max(0,x∗W1+b1)∗W2+b2
这里的全连接层是一个两层的神经网络,先线性变换,然后ReLU非线性,再线性变换。
这里的x就是我们Multi-Head Attention的输出Z,还是引用上面的例子,那么Z是(2,64)维的矩阵,假设W1是(64,1024),其中W2与W1维度相反(1024,64),那么按照上面的公式:
FFN(Z)=(2,64)x(64,1024)x(1024,64)=(2,64),我们发现维度没有发生变化,这两层网络就是为了将输入的Z映射到更加高维的空间中(2,64)x(64,1024)=(2,1024),然后通过非线性函数ReLU进行筛选,筛选完后再变回原来的维度。然后经过Add&Normalize,输入下一个encoder中,经过6个encoder后输入到decoder。
(二)、Decoder
Decoder block。一个decoder由Masked Multi-Head Attention、Multi-Head Attention 和 全连接神经网络FNN构成。比Encoder多了一个Masked Multi-Head Attention,其他的结构与encoder相同,这里重点介绍一下Masked Multi-Head Attention。
1、Decoder的输入:
Decoder的输入分为两类:
一种是训练时的输入,一种是预测时的输入。
训练时的输入就是已经对准备好对应的target数据。例如翻译任务,Encoder输入"I LOVE YOU",Decoder输入"我爱你"。
预测时的输入,一开始输入的是起始符,然后每次输入是上一时刻Transformer的输出。例如,输入"",输出"I",输入"I",输出"I LOVE",输入"我爱",输出"I LOVE YOU",输入"我爱你",输出"我爱你"结束。
2、Masked Multi-Head Attention
与Encoder的Multi-Head Attention计算原理一样,只是多加了一个mask码。mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask。
1.padding mask
因为每个批次输入序列长度是不一样的,所以我们要对输入序列进行对齐。具体来说,就是给在较短的序列后面填充 0。但是如果输入的序列太长,则是截取左边的内容,把多余的直接舍弃。因为这些填充的位置,其实是没什么意义的,所以我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0!
2.sequence mask
sequence mask 是为了使得 decoder 不能看见未来的信息。对于一个序列,在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。这在训练的时候有效,因为训练的时候每次我们是将target数据完整输入进decoder中地,预测时不需要,预测的时候我们只能得到前一时刻预测出的输出。
实现过程为:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。
在Encoder中的Multi-Head Attention也是需要进行mask地,只不过Encoder中只需要padding mask即可,而Decoder中需要padding mask和sequence mask。
Decoder中的第二个Multi-Head Attention就只是基于Attention,它的输入Quer来自于Masked Multi-Head Attention的输出,Keys和Values来自于Encoder中最后一层的输出。第一个Masked Multi-Head Attention是为了得到之前已经预测输出的信息,相当于记录当前时刻的输入之间的信息的意思。第二个Multi-Head Attention是为了通过当前输入的信息得到下一时刻的信息,也就是输出的信息,是为了表示当前的输入与经过encoder提取过的特征向量之间的关系来预测输出。
至此Transformer介绍告一段落。后续会继续保持更新~

