
热门标签
热门文章
- 1c++视觉处理---拉普拉斯金字塔和高斯金字塔
- 2Opencv中人体检测_未定义标识符 "cvlatentsvmdetector
- 3ERROR: [Labtools 27-1832] create_wave_config not a supported tcl command in labtools hardware mode.
- 4Apache POI 在java中处理excel
- 5基于transfomer架构的模型[GPT、BERT、VIT、ST、MAE等等]总结_cycle transfomer 图片
- 6Java可解释性AI是指使用Java编程语言开发的具有可解释性的人工智能系统_java 集成ai可以实现什么功能
- 7git rebase 使用[将其它分支合并到本分支]_如何把其他分支的代码rebase到现在的分支
- 8Java数据结构第三讲-栈/队列_java栈 队列 数据结构
- 9ABAP 数据写入Excel 并保存
- 10如何管理和提升仓储的效率?FineVis带你了解什么是智慧仓储
当前位置: article > 正文
论文笔记:A Time Series is Worth 64 Words: Long-term Forecasting with Transformers_时间序列patch
作者:你好赵伟 | 2024-05-19 09:37:49
赞
踩
时间序列patch
ICLR 2023
比较简单,就不分intro、model这些了
1 核心思想1:patching
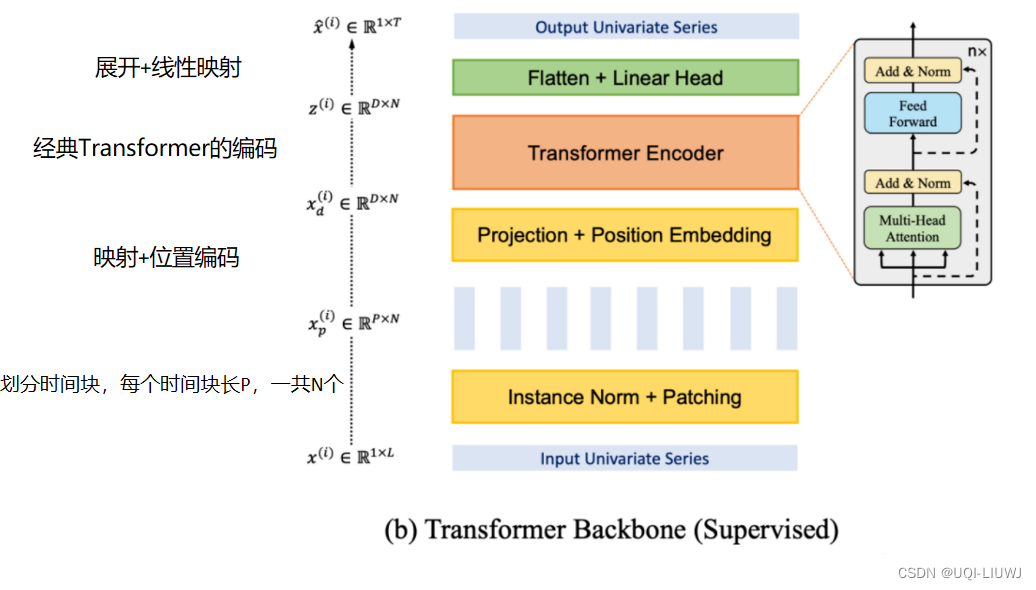
- 给定每个时间段的长度、划分的stride,将时间序列分成若干个时间段
- 时间段之间可以有重叠,也可以没有
- 每一个时间段视为一个token
1.1 使用patching的好处
- 降低复杂度
- Attention 的复杂度是和 token 数量成二次方关系。
- 如果每一个 patch 代表一个 token,而不是每一个时间点代表一个 token,这显然降低了 token 的数量
- 保持时间序列的局部性
- 时间序列具有很强的局部性,相邻的时刻值很接近,以一个 patch 为 Attention 计算的最小单位显然更合理
- 方便之后的自监督表示学习
- 即 Mask 随机 patch 后重建
- 减少预测头的参数量
- L是输入序列长度,M 是序列个数, T是预测序列长度,D是维度,N是patch数量
- 论文中的说法是,不分patch的话,Linear Head的大小是LD×MT
- 这里我觉得有点问题,不分patch的话,输入M*L,经过position embedding+project之后是M*LD,经过Transformer Encoder之后是M*LD,输出是M*T,那么Linear Head的大小应该是LD × T
- 分patch的话LinearHead的大小是ND × T
- 但不管我理解的对于否,分patch的话Linear Head的大小肯定是小
2 核心思想2:channel-independence

- 很多基于Transformer的模型采用了 channel-mixing 的方式
- 指的是,对于多元时间序列,直接将时间序列的所有维度形成的向量投影到嵌入空间以混合多个通道的信息。
- Channel-independence 意味着每个输入 token 只包含来自单个通道的信息。
- 这篇采用了的是Channel-independence
- 将多元时间序列(维度为 M)中每一维单独进行处理
- 即将每一维分别输入到 Transformer Backbone 中
- 将所得预测结果再沿维度方向拼接起来。
- 这相当于将不同维度视为独立的,但 embedding 和 Transformer 的权重在各个维度是共享的。
- 将多元时间序列(维度为 M)中每一维单独进行处理
- 这篇采用了的是Channel-independence
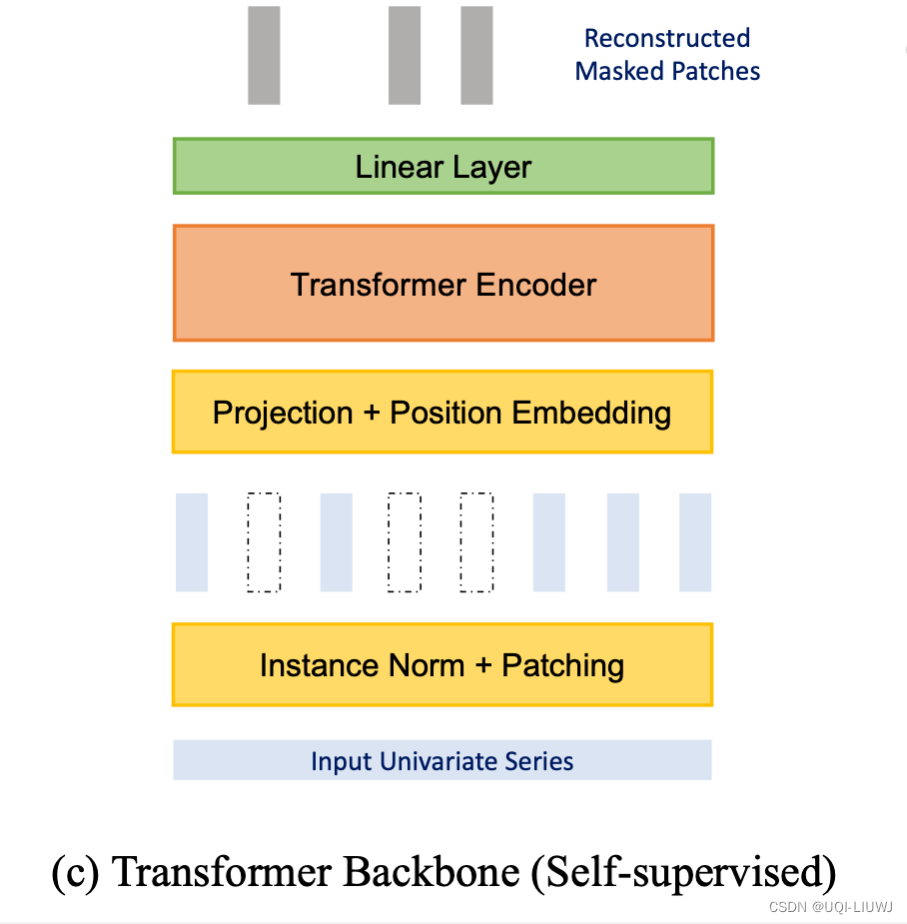
3 自监督表示学习
- 论文说明了分 patch 对 mask 重建来进行自监督学习的好处:mask 一个时间点的话,直接根据相邻点插值就可以重建,这就完全没必要学习了,而 mask 一个 patch 来重建的话则更有意义更有难度。
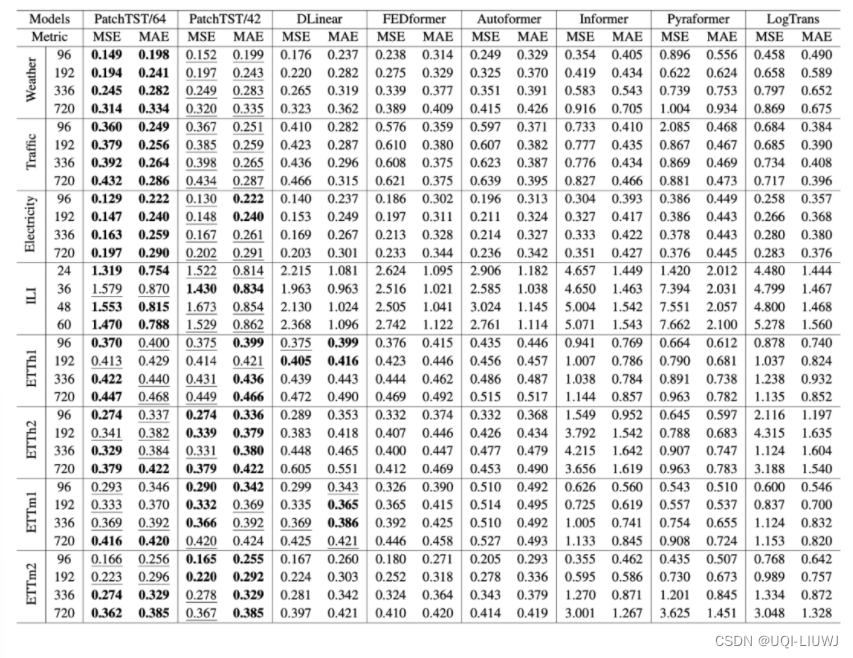
4 实验
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/592302
推荐阅读
相关标签

