
- 1我们是如何测试人工智能的(四)补充:模型全生命周期流程与测试图_智能软件测试模型
- 2Keil的软件仿真和硬件仿真
- 3关于有效解决Ubuntu中出现的若干问题(ROS2系统)_设置ubuntu系统的防火墙设置不会阻止ros2节点间的通信
- 4Go官方限流器time/rate分析_go time.rate
- 5【EI会议征稿通知】第四届云计算与大数据国际学术会议(ICCBD 2024)_2024年第四届iccbd云计算和大数据委员会国际会议2024
- 6微信小程序实现远程控制门锁_微信开发者小程序门禁系统代码怎么写
- 7最强分布式工具Redisson:分布式锁_redisson分布式锁
- 8数据结构 - 二叉树代码实现_创建二叉树的代码数据结构
- 9论文笔记——Generative Adversarial Nets生成对抗网络
- 10基于Android Studio生鲜商城(果蔬商城)_android studio 蔬菜商城项目
KMeans算法( 聚类分析)_kmeans聚类分析
赞
踩
数据集在文末链接
1 聚类分析相关概念
1.1 聚类与分类
分类其实是从特定的数据中挖掘模式,作出判断的过程。比如Gmail邮箱里有垃圾邮件分类器,一开始的时候可能什么都不过滤,在日常使用过程中,我人工对于每一封邮件点选“垃圾”或“不是垃圾”,过一段时间,Gmail就体现出一定的智能,能够自动过滤掉一些垃圾邮件了。这是因为在点选的过程中,其实是给每一条邮件打了一个“标签”,这个标签只有两个值,要么是“垃圾”,要么“不是垃圾”,Gmail就会不断研究哪些特点的邮件是垃圾,哪些特点的不是垃圾,形成一些判别的模式,这样当一封信的邮件到来,就可以自动把邮件分到“垃圾”和“不是垃圾”这两个我们人工设定的分类的其中一个。
聚类的的目的也是把数据分类,但是事先是不知道如何去分的,完全是算法自己来判断各条数据之间的相似性,相似的就放在一起。在聚类的结论出来之前,我完全不知道每一类有什么特点,一定要根据聚类的结果通过人的经验来分析,看看聚成的这一类大概有什么特点。
简而言之,聚类分析,没给定划分类别,根据数据的相似度进行分组的一种方法,分组原则是组内距离最小化而组间距离最大化
1.2 核心思想
通过迭代寻找k个类簇的一种划分方案,使得用这k个类簇的均值来代表相应各类样本时所得的总体误差最小。
k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。k-means算法的基础是最小误差平方和准则,其代价函数是:
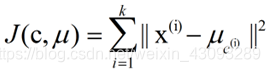
式中,μc(i)表示第i个聚类的均值。
各类簇内的样本越相似,其与该类均值间的误差平方越小,对所有类所得到的误差平方求和,即可验证分为k类时,各聚类是否是最优的。
1.3 算法过程
①从N个样本数据中随机选取K个对象作为初始的聚类质心;
②分别计算每个样本到各个聚类中心的距离,将对象分配到距离最近的聚类中;
③所有对象分配完成之后,重新计算K个聚类的质心;
④与前一次的K个聚类中心比较,如果发生变化,重复步骤②,否则转到⑤;
⑤当质心不在发生变化时,停止聚类过程,并输出聚类结果;
伪代码:
随机选择K个点作为初始质心点
当任意一个点的簇分配结果发生改变时
对数据集中的每一个数据点
对每一个质心
计算质心与数据点的距离
将数据点分配到距离最近的簇
对每一个簇,计算簇中所有点的均值,并将均值作为质心
1.4 KMeans主要参数
- sklearn.cluster.KMeans(
- n_cluster = 8, #簇的个数,即拟聚成几类
- init = "k-means++", #初始簇中心的获取方法
- n_init = 10, #获取初始簇中心的迭代次数,为了弥补初始质心的影响,算法默认会初始10次质心,实现算法,然后返回最优的结果
- max_iter = 300, #最大迭代次数,(K-Means算法的实现需要迭代)
- tol = 0.0001, #容忍度,即K_Means运行准则收敛的条件
- precomoputer_distance = "auto", #用于确认是否需要提前计算距离,有三个值可选,auto,True,False,默认auto,
- "auto":如果样本数乘以聚类数(feature*samples)大于12*6则不计算距离.True:总是预算距离,Flase永不预算距离
- verbose = 0, #冗长模式
- random_state = None, #随机生成簇中心的状态条件
- copy_x = True, #是否修改一条数据的标记,如果为True.即复制不修改源数据。bool在sklearn接口中都用到这个参数,即是否对输入的数据继续
- copy操作,以便不修改用户的输入数据。
- n_jobs = 1, #默认1,计算所用进程数,几核并行,若为-1,则用所有的CPU进行计算,若值为1,不进行并行运算,以方便调试,。
- 若为-1,所用CPU(n_cpus+1+n_jobs),值为-2,则用到的CPU为总CPU数减1
- algorithm = "auto" #KMeans的实现算法,有auto,full,elkan3种状态,其中full表示用EM方式实现
- )
2 问题的提出:
航空公司经常会对客户进行分类,那么怎样对客户分群,才能区分高价值客户、无价值客户等,
并对不同的客户群体实施个性化的营销策略,以实现利润最大化?
餐饮企业也会经常碰到此类问题。如何通过对客户的消费行为来评价客户 对企业的贡献度,
从而提高对某些客户群体的关注度,以实现企业利润的最 大化?如何通过客户对菜品的消费明细,
来判断哪些菜品是招牌菜(客户必点),哪些又是配菜(点了招牌菜或许会点的菜品),以此来提高餐饮的精准采购?
3 模型的建立
对于上面的情景,可使用聚类分析方法处理。
根据航空公司目前积累的大量客户会员信息及其乘坐的航班记录,可以得到包括姓名、乘机的间隔、乘机次数 、消费金额等十几条属性信息。
本情景案例是想要获取客户价值,识别客户价值应用的最广泛的模型是RFM模型,三个字母分别代表Recency(最近消费时间间隔)、
Frequency(消费频率)、 Monetary(消费金额)这三个指标。结合具体情景,最终选取客户消费时间间隔R、消费频率F、消费金额M这三个指标作为
航空公司识别客户价值的指标。
为了方便说明操作步骤,本案例简单选择三个指标进行K-Means聚类分析来识别出最优价值的客户。航空公司在真实的判断客户类别时,
选取的观测维度要大得多。
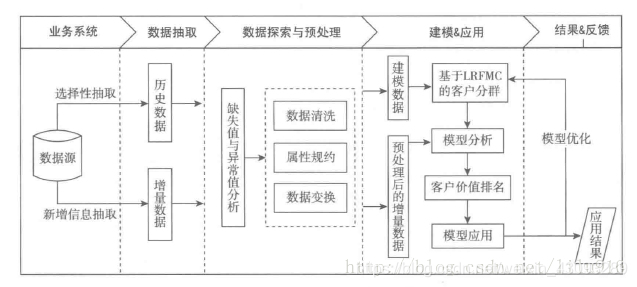
本情景案例的 主要步骤包括 :
(1)对数据集进行清洗处理,包括数据缺失与异常处理、数据属性的规 约、数据清洗和变换,把数据处理成可使用的数据( Data);
(2)利用已预 处理的数据(data),基于盯M 模型进行客户分群,对各个 客户群进行特征分析,对客户进行分类;
(3)针对不同 类型的客户制定不同的营销政策,实行个性化服务。
4 Python 代码实现
步骤一: 参数初始化
- from pylab import mpl
- mpl.rcParams['font.sans-serif'] = ['SimHei']
- mpl.rcParams['axes.unicode_minus'] = False
-
- import pandas as pd
- from matplotlib import pyplot as plt
- from sklearn.cluster import KMeans
- from pandas import Series,DataFrame
- import time
-
- class KMeans_AirPlane(object):
- def __init__(self):
- self.data = pd.read_excel(r'./files/AirPlane.xlsx',index_col="Id",sheet_name=0,encoding="utf-8-sig") #读取数据
- self.cleanedfile = r'./files/CleanedData.xls' #数据清洗后的结果文件
- self.zscoredfile = r'./files/ZscoredData.xls' #标准化后的数据文件
- self.outputfile = r'./files/DataType.xls' #样本类别对应的文件
- self.outputpic = "./files/pd_" #概率密度图文件名前缀
- self.k = 3 #聚类的类别
- self.maxIteration = 500 #聚类最大循环数
步骤二: 读取数据,清洗:去除缺失数据,对部分数据转化
- def cleanData(self):
- df = self.data.drop_duplicates() #以防万一,去除重复数据
- df = df[df["Monetary"].notnull()] #保留总消费非空的数据 inuc 877行
-
- #瞎处理的数据,练习练习
- index1 = df["Recency"] != 0
- index2 = df["Frequency"] != 0
- index3 = (df["Monetary"] != 0)&(df["Frequency"] != 0) #逻辑与
- df = df[index1 | index2 | index3] # 逻辑或
- try:
- df.to_excel(self.cleanedfile)
- except:
- print("数据清理保存失败。")
- else:
- print("数据清理完成,保存成功。")
步骤三: 标准化处理
- def standard(self):
- data = pd.read_excel(self.cleanedfile,encoding="utf-8-sig",index_col="Id",sheet_name=0)#读取处理后的数据
- data = (data-data.mean(axis=0)) / data.std(axis=0) #数据表标准化
- try:
- data.to_excel(self.zscoredfile,index=False) #标准化后数据写入zscoredfile
- except:
- print("数据标准化失败。")
- else:
- print("数据标准化成功。")
步骤四: K-Means算法聚类消费行为特征数据
- def kmeansProcessData(self):
- kdata = pd.read_excel(self.zscoredfile,encoding="utf-8-sig")
- #分为k类;n_jobs为并发数,一般最好等于CPU核数;
- kmodel = KMeans(n_clusters=self.k,n_jobs=4,max_iter=self.maxIteration)
- kmodel.fit(kdata) #训练模型,开始聚类
- # print(kmodel)
-
- r1 = Series(kmodel.labels_).value_counts() #统计各个类别的数目
- r2 = DataFrame(kmodel.cluster_centers_) #找出聚类中心
- r = pd.concat([r1,r2],axis=1)
- r.columns = list(kdata.columns) + [u"类别数目"] #重命名表头
- # print(r)
- '''
- Recency Frequency Monetary 类别数目
- 0 520 -0.165820 -0.671795 -0.299179
- 1 339 -0.147391 1.070541 0.403429
- 2 40 3.405259 -0.295940 0.487837
- '''
- r = pd.concat([kdata,Series(kmodel.labels_,index=kdata.index)],axis=1)
- r.columns = list(kdata.columns) + [u'聚类类别'] #重命名表头
- # print(r)
- '''
- Recency Frequency Monetary 聚类类别
- 0 0.309287 1.024322 0.303116 2
- 1 -1.161483 1.300817 0.992527 2
- 2 -0.646714 -0.772894 -0.628962 1
- 3 -0.499637 -0.081657 0.484777 1
- 4 -0.940868 -0.911141 1.072565 1
- .. ... ... ... ...
- 894 0.309287 -0.496399 0.698166 1
- 895 -1.161483 1.439064 1.316807 2
- 896 -0.279021 2.406796 -0.481132 2
- 897 -0.058405 -0.496399 -0.457503 1
- 898 2.883135 -0.772894 1.198429 0
-
- [899 rows x 4 columns]
- '''
- try:
- r.to_excel(self.outputfile,encoding="utf-8-sig")
- except:
- print("数据聚类分析失败")
- else:
- print("数据聚类分析成功!!!")
步骤五:导出各自类别的概率密度图
- def dent_plt_pic(self,kdata,index):
- p = kdata.plot(kind='kde', linewidth=2, subplots=True, sharex=False)
- [p[i].set_ylabel(u'密度') for i in range(self.k)]
- plt.xlabel('分群%s'%(int(index)+1))
- plt.legend()
- return plt
- def plt_pic(self):
- kdata = pd.read_excel(self.outputfile, encoding="utf-8-sig")
- cdata = pd.read_excel(self.cleanedfile,encoding="utf-8-sig")
- time.sleep(1)
- for i in range(self.k):
- self.dent_plt_pic(cdata[kdata[u'聚类类别']==i],index=i).savefig(u'%s%s.png'%(self.outputpic, i))
- print("概率密度函数图文绘画完毕!!")
整体代码
- # -*- coding: UTF-8 -*-
- '''
- @Author :Jason
- '''
- from pylab import mpl
- mpl.rcParams['font.sans-serif'] = ['SimHei']
- mpl.rcParams['axes.unicode_minus'] = False
-
- import pandas as pd
- from matplotlib import pyplot as plt
- from sklearn.cluster import KMeans
- from pandas import Series,DataFrame
- import time
-
- class KMeans_AirPlane(object):
- def __init__(self):
-
- self.data = pd.read_excel(r'./files/AirPlane.xlsx',index_col="Id",sheet_name=0,encoding="utf-8-sig") #读取数据
- self.cleanedfile = r'./files/CleanedData.xls' #数据清洗后的结果文件
- self.zscoredfile = r'./files/ZscoredData.xls' #标准化后的数据文件
- self.outputfile = r'./files/DataType.xls' #样本类别对应的文件
- self.outputpic = "./files/pd_" #概率密度图文件名前缀
- self.k = 3 #聚类的类别
- self.maxIteration = 500 #聚类最大循环数
-
-
- def cleanData(self):
- df = self.data.drop_duplicates() #以防万一,去除重复数据
- df = df[df["Monetary"].notnull()] #保留总消费非空的数据 inuc 877行
-
- #瞎处理的数据,练习练习
- index1 = df["Recency"] != 0
- index2 = df["Frequency"] != 0
- index3 = (df["Monetary"] != 0)&(df["Frequency"] != 0) #逻辑与
- df = df[index1 | index2 | index3] # 逻辑或
- try:
- df.to_excel(self.cleanedfile)
- except:
- print("数据清理保存失败。")
- else:
- print("数据清理完成,保存成功。")
- def standard(self):
- #此函数用来将数据标准化
- data = pd.read_excel(self.cleanedfile,encoding="utf-8-sig",index_col="Id",sheet_name=0)#读取处理后的数据
- data = (data-data.mean(axis=0)) / data.std(axis=0) #数据表标准化
- try:
- data.to_excel(self.zscoredfile,index=False) #标准化后数据写入zscoredfile
- except:
- print("数据标准化失败。")
- else:
- print("数据标准化成功。")
- def kmeansProcessData(self):
- kdata = pd.read_excel(self.zscoredfile,encoding="utf-8-sig")
- #分为k类;n_jobs为并发数,一般小于CPU核数;
- kmodel = KMeans(n_clusters=self.k,n_jobs=4,max_iter=self.maxIteration)
- kmodel.fit(kdata) #训练模型,开始聚类
- # print(kmodel)
-
- r1 = Series(kmodel.labels_).value_counts() #统计各个类别的数目
- r2 = DataFrame(kmodel.cluster_centers_) #找出聚类中心
- r = pd.concat([r1,r2],axis=1) #1横向连接,得到聚类中心对应的类别下的数目
- r.columns = list(kdata.columns) + [u"类别数目"] #重命名表头
- # print(r)
- '''
- Recency Frequency Monetary 类别数目
- 0 520 -0.165820 -0.671795 -0.299179
- 1 339 -0.147391 1.070541 0.403429
- 2 40 3.405259 -0.295940 0.487837
- '''
- r = pd.concat([kdata,Series(kmodel.labels_,index=kdata.index)],axis=1)
- r.columns = list(kdata.columns) + [u'聚类类别'] #重命名表头
- # print(r)
- '''
- Recency Frequency Monetary 聚类类别
- 0 0.309287 1.024322 0.303116 2
- 1 -1.161483 1.300817 0.992527 2
- 2 -0.646714 -0.772894 -0.628962 1
- 3 -0.499637 -0.081657 0.484777 1
- 4 -0.940868 -0.911141 1.072565 1
- .. ... ... ... ...
- 894 0.309287 -0.496399 0.698166 1
- 895 -1.161483 1.439064 1.316807 2
- 896 -0.279021 2.406796 -0.481132 2
- 897 -0.058405 -0.496399 -0.457503 1
- 898 2.883135 -0.772894 1.198429 0
-
- [899 rows x 4 columns]
- '''
- try:
- r.to_excel(self.outputfile,encoding="utf-8-sig")
- except:
- print("数据聚类分析失败")
- else:
- print("数据聚类分析成功!!!")
-
- def dent_plt_pic(self,kdata,index):
- '''
- 自定义作图函数
- :return:
- '''
- p = kdata.plot(kind='kde', linewidth=2, subplots=True, sharex=False)
- [p[i].set_ylabel(u'密度') for i in range(self.k)]
- plt.xlabel('分群%s'%(int(index)+1))
- plt.legend()
- return plt
-
- def plt_pic(self):
- kdata = pd.read_excel(self.outputfile, encoding="utf-8-sig")
- cdata = pd.read_excel(self.cleanedfile,encoding="utf-8-sig")
- print(kdata)
- time.sleep(1)
- for i in range(self.k):
- self.dent_plt_pic(cdata[kdata[u'聚类类别']==i],index=i).savefig(u'%s%s.png'%(self.outputpic, i))
- print("概率密度函数图文绘画完毕!!")
-
- if __name__ == "__main__":
- km = KMeans_AirPlane()
- km.main()
5 分类结果与相应分析
类别数目和聚类类别在代码中已有相应的print,如下:
- '''
- Recency Frequency Monetary 类别数目
- 0 520 -0.165820 -0.671795 -0.299179
- 1 339 -0.147391 1.070541 0.403429
- 2 40 3.405259 -0.295940 0.487837
- '''
-
- '''
- Recency Frequency Monetary 聚类类别
- 0 0.309287 1.024322 0.303116 2
- 1 -1.161483 1.300817 0.992527 2
- 2 -0.646714 -0.772894 -0.628962 1
- 3 -0.499637 -0.081657 0.484777 1
- 4 -0.940868 -0.911141 1.072565 1
- .. ... ... ... ...
- 894 0.309287 -0.496399 0.698166 1
- 895 -1.161483 1.439064 1.316807 2
- 896 -0.279021 2.406796 -0.481132 2
- 897 -0.058405 -0.496399 -0.457503 1
- 898 2.883135 -0.772894 1.198429 0
-
- [899 rows x 4 columns]
- '''
各分群的概率密度图像如下:
分群1:

分群2:

分群3:

分析:
分群1客户特点:
Recency 间隔分布在0-30天,Frequency集中在0-12次,Monetray在0-2000元之间
分群2客户特点:
Recency 间隔分布在0-30天,Frequency集中在10-24次,Monetray在0-2000元之间
分群3客户特点:
Recency 间隔分布在25-100天,Frequency集中在0-18次,Monetray在0-2000元之间
对比分析:
基于特征描述,本案例定义4个等级的客户案例:重要保持客户、重要发展客户、重要挽留客户、一般客户或低价值客户,每种客户类型特征如下:
1、重要保持客户:最近乘坐公司航班(R)较低,乘坐的次数(F)或总消费额度(M)较高。这类客户对航空公司贡献最高,应尽可能延长这类客户的高消费水平。
2、重要发展客户:最近乘坐公司航班(R)较低,乘坐的次数(F)或总消费额度(M)较低。这类客户是航空公司的潜在价值客户,需要努力促使增加他们的乘机消费。
3、重要挽留客户:乘坐的次数(F)或总消费额度(M)较高,但最近乘坐公司航班(R)较低,很久没有乘坐本公司的航班,原因各不相同,需要采取一定的营销手段,延长客户的生命周期。
4、一般与低价值客户:乘坐的次数(F)或总消费额度(M)较低,最近乘坐公司航班(R)很高,他们是公司的低价值客户,可能只在航空公司打折的时候才会乘坐航班。
可以看出重要保持客户、重要发展客户、重要挽留客户是最具价值的前三名客户类型,为了深度挖掘航空公司各类型客户的价值,需要提升重要发展客户的价值、稳定和延长重要保持客户的高水平消费、对重要挽留客户积极进行关系恢复,并策划相应的营销策略加强巩固客户关系。
链接:https://pan.baidu.com/s/145mi9UUi9rm8RHOmceThhw
提取码:v7g9
参照:《基于Python的大数据分析基础及实战》

