
MOSFET数字孪生实战【Python】_半导体行业数字孪生
赞
踩
本文将介绍如何使用 Python 构建电子开关(晶体管)的数字孪生。
1、什么是数字孪生?
IBM 将数字孪生定义如下“数字孪生是一种旨在准确反映物理对象的虚拟模型”,并指出创建数字孪生的主要促成因素是如何收集数据的传感器和以某种特定格式/模型将数据插入到对象的数字副本中的处理系统。
此外,IBM 表示,“一旦获知此类数据,虚拟模型可用于运行模拟、研究性能问题并产生可能的改进”。
所以,我们可以画出这个心智模型:

2、使用 Python 创建数字孪生
那么,如何使用我们最喜欢的语言 Python 来创建数字孪生呢?为什么我们甚至认为它会起作用?
答案很简单。只需看上图,然后再看下图,就可以看到数字孪生模型和经典 Python 对象之间的等价关系。我们可以使用合适的方法/函数模拟传感器和数据处理器,将收集到的数据存储在数据库或内部变量中,并将所有内容封装到 Python 类中。

一旦我们完成了这一点,也可以希望 Python 对象
- 可用于合适的模拟程序,
- 可以探测数据,并且
- 甚至可以接受优化程序以增强合适的内部参数。
当然,我们可以为该方案添加几乎无限的复杂层,并使对象成为真正复杂的数字构造。但是,遵循奥卡姆剃刀原则,我们应该从简单开始,然后逐步增加复杂性。
…创建数字孪生的主要促成因素是收集数据的传感器和处理系统……
在本文中,我们将采用简单的分步方法从单个半导体器件(物理对象)中创建数字孪生对象。为了简单起见,我们甚至不会对传感器进行建模,而是将它们模拟为半导体器件上的简单端电压。
3、物理对象 - MOSFET 器件
我们周围有一些物理对象体现了现代文明的进程。不完整的列表可能如下所示,
- 内燃机——体现了所有的机动性
- 印刷机——包含所有知识
- 电动机——体现所有工业运动
- 基于半导体的晶体管 - 体现了所有电子/互联网
在加入数据科学领域之前,我在半导体行业工作了十多年。自然,我会被这个数字孪生演示的相关示例所吸引。

那么,什么是MOSFET?
尽管最早的半导体晶体管是所谓的“双极结器件”,但几乎所有现代晶体管都是称为 MOSFET 的形式。它是一个缩写词,代表“金属-氧化物-半导体场-效应-晶体管”。
基本上,它是一种由金属和半导体(例如硅或锗)层制成的器件,中间夹着一层薄的氧化物(或其他电绝缘体)材料层。
这是最早的MOSFET专利之一的历史形象,

我们可以通过采用具有三个端子(漏极、源极和栅极)的器件模型(也称为电路模型)来简化内部结构。

4、我们要建模的MOSFET特征
这是构建数字孪生时的首要考虑因素之一——我们想要在数字对象中建模哪些特征。这决定了孪生的复杂性和数据结构选择。
例如,虽然我们可以用 MOSFET 结构来模拟各种复杂的物理现象,但我们可能会选择将自己限制在只模拟最基本的特性,即。最简单形式的漏源电流和电压关系。

现在,我们没有足够的时间在本文中详细解释所有这些特征(及其基础物理)。有兴趣的读者可以参考优秀的网上资料。
5、MOSFET是数字开关
记住 MOSFET 行为的最简洁方法是将其想象为数字开关。下面是它的工作原理,
- 如果Gate和Source之间的电压低于某个阈值,则开关关闭,并且在Drain和Source之间没有电流(或信息)流动。这显示在上图的右下角。
- 当栅极到源极电压高于此阈值时,开关打开。漏源电流也由它们之间的电压决定。这显示在上图的右上角。
因此,MOSFET 的基本用途是作为电压控制开关,即我们可以通过控制第三个端子上的电压来控制其两个端子之间的电流(或信息)量。
我们想在数字对象中建模哪些特征?这决定了数字孪生的复杂性和数据结构选择
考虑到这一点,创建数字孪生唯一要记住的是通用 MOSFET 的三个重要参数,
- Vth:它是阈值电压(在Gate和Source之间),高于该阈值,开关就会导通。
- gm:这是 MOSFET 在导通后可以在漏极和源极之间传输电流的“简易性” 。这个数字越高,电流越大。它可以被认为是电阻的倒数(表示给定电压下电流流动的电阻)。
- BV:这称为“击穿电压”。这没有在理想的开关描述中讨论,也不会在数字孪生中建模。这代表了 MOSFET 在其处于关断状态时可以在其漏极和源极之间保持多少电压的限制。超过此限制,MOSFET 再次开始导通,但不是以受控方式,即我们无法控制电流,它基本上是无用的。但是,此参数对于设计和建模很重要,因为它限制了特定应用中特定设备的选择。
记住,MOSFET 的基本用途是作为电压控制开关……
6、Python 数字孪生
此演示的样板代码在Github 库中。为简洁起见,我将仅在本文中展示部分代码片段。
6.1 MOSFET类
我们定义了主要的 MOSFET 类,用户可以选择还定义一些参数和端电压。部分代码如下所示:
class MOSFET: def __init__(self,params=None,terminals=None): # Params if params is None: self._params_ = {'BV':20, 'Vth':1.0, 'gm':1e-2} else : self._params_ = params # Terminals if terminal is None: self._terminals_ = {'source':0.0, 'drain':0.0, 'gate':0.0} else: self._terminals_ = terminal

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
在这段代码中,可以观察到我们之前详细讨论过的熟悉的终端和参数。有一些默认参数。
我们也可以有一种__repr__方法来用一行来描述对象:
def __repr__(self):
return "Digital Twin of a MOSFET"
- 1
- 2
6.2 一种确定开关状态的方法
通过在类中定义一个方法,我们可以轻松地将数字开关(ON/OFF)的 MOSFET 特性转换为编程逻辑。
def determine_state(self,vgs=None):
"""
"""
if vgs is None:
vgs = self._terminals_['gate'] - self._terminals_['source']
else:
vgs = vgs
if vgs > self._params_['Vth']:
return 'ON'
else:
return 'OFF'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在该__init__方法中,我们可以从对象的实例化中确定状态。
# Determine state
self._state_ = self.determine_state()
- 1
- 2
我们已经掌握了定义具有特征和行为的数字孪生的窍门,对吧?
6.3 快速示例
在深入探讨其他特征之前,让我们先看看迄今为止定义的这个数字孪生的行为。
mosfet = MOSFET()
- 1
在Jupyter notebook中,我们输入这个来测试一行描述:
mosfet
>> Digital Twin of a MOSFET
- 1
- 2
我们测试mosfet对象的状态:
mosfet._state_
>> 'OFF'
- 1
- 2
我们以这种方式获取默认参数的字典:
mosfet._params_
>> {'BV': 20, 'Vth': 1.0, 'gm': 0.01}
- 1
- 2
现在,如果我们显式定义一个带有一些终端和参数值的对象:
mosfet = MOSFET(terminals={'source':0.0,
'drain':0.0,
'gate':2.0},
params={'BV':20,
'Vth':1.0,
'gm':1e-2})
- 1
- 2
- 3
- 4
- 5
- 6
你认为这个对象的状态是什么?让我们看一下:
mosfet._state_
>> 'ON'
- 1
- 2
MOSFET(或其数字孪生)处于打开状态,因为栅极和源极之间的电压大于实例中定义的参数Vth 。我再次重复代码片段,突出显示感兴趣的部分:
terminals={'source':0.0,
'drain':0.0,
'gate':2.0}
- 1
- 2
- 3
以及:
params={'BV':20,
'Vth':1.0,
'gm':1e-2})
- 1
- 2
- 3
6.4 具有分析模型的方法
接下来,我们使用简单的一阶分析模型计算导通状态 MOSFET 的漏源电流。代码和方程式都包含在Notebook中,这里我只展示部分代码片段:
def id_vd(self,vgs=None,vds=None,rounding=True):
"""
Calculates drain-source current from
terminal voltages and gm
"""
<code>
if state=='ON':
if vds <= vgs - vth:
ids = self._params_['gm']*(vgs - vth - (vds/2))*vds
else:
ids = (self._params_['gm']/2)*(vgs-vth)**2
<more code...>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
更有趣的是,检查数字孪生是否可以产生类似于物理设备的电流-电压特性。我们可以为一系列漏源电压计算一系列漏源电流:
ids = []
mosfet = MOSFET()
vds_vals = [0.01*i for i in range(1,501)]
for v in vds_vals:
ids.append(mosfet.id_vd(vgs=3.0,vds=v,rounding=False))
- 1
- 2
- 3
- 4
- 5
结果看起来与通用的理想 MOSFET 特性完美匹配。这里Vds(x轴)代表漏极-源极电压,Ids(y轴)代表漏极-源极电流:

分析模型也涉及栅极-源极电压 (Vgs),因此,我们可以计算一系列 Vgs 的 Ids 与 Vds 曲线。结果看起来像:

7、现代数字孪生—深度学习
数字孪生建模不一定需要来自数据科学或机器学习的工具。然而,在以数据驱动模型为主的现代世界中,在适用和合适的地方使用此类建模技术是谨慎的。
这并不意味着您应该从数字孪生中消除所有分析模型,并开始在每个特征上投入深度学习模型。作为领域专家(或者如果你不是领域专家,则在专家的帮助下),必须确定分析和机器学习模型(甚至离散仿真模型)的平衡组合,以嵌入到数字孪生对象中以表示实物资产的真实世界特征。

记住:数字孪生建模不一定需要来自数据科学或机器学习的工具。
7.1 使用神经网络对亚阈值泄漏进行建模
那么,我们应该在我们的数字孪生对象中应用合适的机器学习技术吗?事实证明,计算(或使用 ML 估计器预测)所谓的“亚阈值泄漏”将是一个很好的选择。
这是什么“亚阈值泄漏”?
如前所述,当 Vgs 低于 Vth 时,MOSFET 处于关断状态。因此,它的理想行为是在漏极和源极之间承载零电流。然而,由于奇妙的量子力学(我们不需要知道细节),一个真正的 MOSFET 即使在关断状态下也会携带少量的“泄漏”电流。我们可以尝试使用 ML 模型(特别是深度神经网络 (DNN))来计算这一点。
7.2 ML 模型——为什么以及如何选择?
那么,为什么我们选择一个解析方程来模拟导通状态下的 Ids-Vds 和一个 DNN 来模拟漏电流呢?
这个问题没有正确或错误的答案。这取决于几个因素,
- 你拥有的数据的类型和性质
- 你尝试建模的物理过程的性质和复杂性
- 数字孪生模型的性能和准确性之间的权衡
在这种情况下,泄漏电流的测量通常是嘈杂的。实际值也具有一定的随机性,这是创建物理 MOSFET 的材料特性和制造工艺的自然变化的强大函数。物理学还表明它是端电压和一些其他内部参数的非线性函数。所有这些都使得 ML 方法适用于对这一特征进行建模。
对于创建的每个数字孪生,我们都必须深入调查并根据判断做出选择。然而,数字孪生的美妙之处在于,它允许你随时用 ML 模型替换分析模型(反之亦然)。
必须确定分析和机器学习模型(甚至离散仿真模型)的平衡组合,以嵌入到数字孪生对象中
7.3 模型训练方法
模型训练和预测接口的选择是完全灵活的。在这个例子中,我们有单独的训练和预测方法。训练方法的代码片段如下所示。
def train_leakage(self,data=None,
batch_size=5,
epochs=20,
learning_rate=2e-5,
verbose=1):
"""
Trains the digital twin for leakage current model with experimental data
Args:
data: The training data, expected as a Pandas DataFrame
batch_size (int): Training batch size
epochs (int): Number of epochs for training
learning_rate (float): Learning rate for training
verbose (0 or 1): Verbosity of display while training
"""
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
请注意,任何了解构建深度学习模型的人都熟悉的参数,如batch_size、epochs和—。learning_rate作为主要输入,你只需要提供data ,一个 Pandas DataFrame。
在内部,代码构建了一个 Tensorflow Keras 模型,对其进行编译和训练,并将训练好的模型保存为 Digital Twin 的内部属性 ( self.leakage_model)。
# Deep-learning model
model = build_model(num_layers=3,
architecture=[32,32,32],
input_dim=3)
# Compile and train
model_trained = compile_train_model(model,
X_train_scaled,
y_train_scaled,
batch_size=batch_size,
epochs=epochs,
learning_rate=learning_rate,
verbose=verbose)
self.leakage_model = model_trained
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
像隐藏层的数量和激活函数这样的超参数在这个实现中是预先固定的,但是它们可以很容易地暴露给在实际应用程序中使用数字孪生的开发人员。
数字孪生的美妙之处在于它允许你随时将分析模型替换为 ML 模型(反之亦然)
7.4 机器学习的数据源
对于这个演示,我们使用特殊的辅助函数(包含在Notebook中)创建了一些合成数据来训练 DNN。该助手包括随机变量,以模拟前面提到的制造和测量中的可变性和噪声。
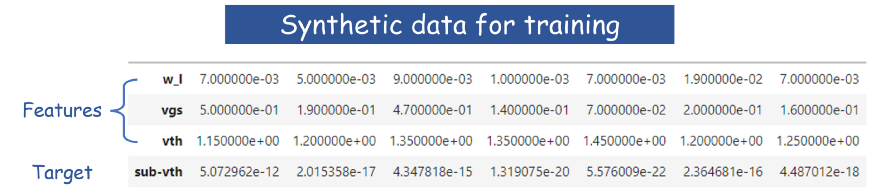
然而,在现实生活中,半导体工厂/晶圆厂将在数百万个 MOSFET 上运行物理测试套件(使用其他机器),并记录它们在各种 Vgs 偏置电压下的泄漏电流。它还将记录测试中这些 MOSFET 的 Vth。所有这些数据都将流入数字孪生模型,模型将被不断训练和更新。

通过这种安排,我们只需要编写一行代码来使用作为dfDataFrame 提供的训练数据来训练模型:
mosfet.train_leakage(df)
- 1
熟悉的训练开始了:
7.5 预测方法
我们编写了一个单独的泄漏方法来预测作为输入的跨导、Vgs 和 Vth 的任意组合的 sub-Vth 泄漏:
def leakage(self, w_l=1e-2, vgs=None, vth=None): """ Calculates leakage current using the deep learning model """ if not self._leakage_: return "Leakage model is not trained yet" # Vgs if vgs is None: vgs = self._terminals_['gate'] - self._terminals_['source'] else: vgs = vgs # Vth if vth is None: vth = self._params_['Vth'] else: vth = vth # Predict x = np.array([w_l,vgs,vth]) ip = x.reshape(-1,3) result = float(10**(-self.leakage_model.predict(ip))) return result
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
代码中的幂运算(提高到 10 次方)是因为我们提供了实际泄漏值的负 10 对数作为 DNN 模型的训练目标。这样做是为了实现更快的收敛和更高的准确性。
8、结束语
在本文中,我们只是通过展示 Python 编程框架的一些简单步骤来剥离数字孪生设计的上层。如何为选择的系统/资产添加更复杂的编程层、逻辑层和数据科学层,并设计强大的数字孪生,这还取决于读者自己。
工业 4.0/智能工厂已经到来,并准备好利用数字化转型、人工智能和机器学习方面的所有进步。数字孪生是这一旅程的重要组成部分。

