
热门标签
热门文章
- 11.14 什么是蜜罐_低交互蜜罐
- 2YOLO-V5分类实战系列 —— 调优自己的数据集+RK1808部署_yolov5实战
- 3小议C++中const的实现机制_const struct (long)&
- 4java中几个时间的区别(java.sql.date,java.sql.time,java.sql.Timestamp)_java中 java.sql.date 时间比较
- 5马踏棋盘算法_马踏棋盘的规则
- 6CentOs搭建Kubernetes集群
- 7android自定义通知声音无效,Android通知Notification设置setSound无效解决办法
- 8Centos系统下安装Ambari
- 9使用Jprofiler分析内存溢出场景_jprofiler分析hprof文件
- 10final修饰的变量有三种
当前位置: article > 正文
头歌实训--机器学习(决策树)_头歌sklearn中的决策树
作者:小蓝xlanll | 2024-05-18 10:45:33
赞
踩
头歌sklearn中的决策树
第1关:决策树简述
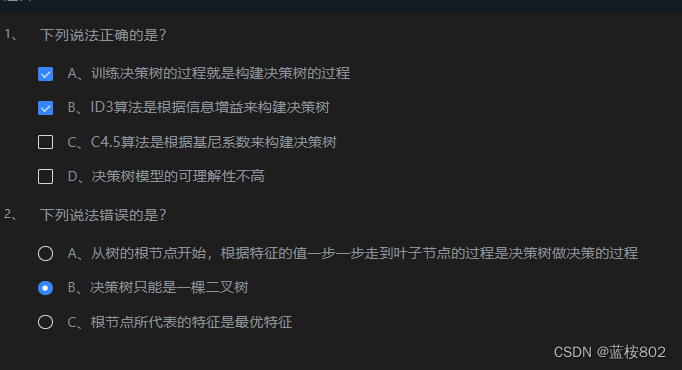
第2关:决策树算法详解
- import numpy as np
- from sklearn import datasets
-
- #######Begin#######
- # 划分函数
- def split(x,y,d,value):
- index_a=(x[:,d]<=value)
- index_b=(x[:,d]>value)
- return x[index_a],x[index_b],y[index_a],y[index_b]
- #######End#########
-
- #######Begin#######
- # 信息熵的计算
- from collections import Counter
- from math import log
-
- def entropy(y):
- length = len(y)
- counter = {}
- for item in y:
- counter[item] = counter.get(item, 0) + 1
- res= 0
- for _, cnt in counter.items():
- p = float(cnt) / length
- res =np.sum(-p*np.log(p))
- return res
-
- #######End#########
-
- #######Begin#######
- # 计算最优划分属性和值的函数
- def try_spit(x,y):
- best_entropy=float("inf")
- best_d,best_v=-1,-1
- for d in range(x.shape[1]):
- sorted_index=np.argsort(x[:,d])
- for i in range(1,len(x)):
- if x[sorted_index[i-1],d] != x[sorted_index[i],d]:
- v=(x[sorted_index[i-1],d]+x[sorted_index[i],d])/2
- x_l,x_r,y_l,y_r=split(x,y,d,v)
- e=entropy(y_l)+entropy(y_r)
- if e<best_entropy:
- best_entropy,best_d,best_v=e,d,v
- return best_entropy,best_d,best_v
- #######End#########
-
-
- # 加载数据
- d=datasets.load_iris()
- x=d.data[:,2:]
- y=d.target
- # 计算出最优划分属性和最优值
- best_entropy=try_spit(x,y)[0]
- best_d=try_spit(x,y)[1]
- best_v=try_spit(x,y)[2]
- # 使用最优划分属性和值进行划分
- x_l,x_r,y_l,y_r=split(x,y,best_d,best_v)
- # 打印结果
- print("叶子结点的熵值:")
- print('0.0')
- print("分支结点的熵值:")
- print('0.6931471805599453')

第3关:sklearn中的决策树
- from sklearn.tree import DecisionTreeClassifier
-
- def iris_predict(train_sample, train_label, test_sample):
- '''
- 实现功能:1.训练模型 2.预测
- :param train_sample: 包含多条训练样本的样本集,类型为ndarray
- :param train_label: 包含多条训练样本标签的标签集,类型为ndarray
- :param test_sample: 包含多条测试样本的测试集,类型为ndarry
- :return: test_sample对应的预测标签
- '''
-
- # ************* Begin ************#
- tree_clf = DecisionTreeClassifier(splitter="random")
- tree_clf = tree_clf.fit(train_sample, train_label)
- y_pred = tree_clf.predict(test_sample)
- return y_pred;
-
- # ************* End **************#
第4关:基于决策树模型的应用案例
- #根据编程要求,补充下面Begin-End区间的代码
- import numpy as np
- import pandas as pd
- import numpy as np
- import pandas as pd
- from sklearn.tree import DecisionTreeClassifier, export_graphviz # 导入决策树模型
- from sklearn.model_selection import train_test_split # 导入数据集划分模块
- import matplotlib.pyplot as plt
- from sklearn.metrics import roc_auc_score
- from sklearn.metrics import classification_report
-
- # 数据的读入与处理
- data_path ='/data/bigfiles/7db918ff-d514-49ea-8f6b-ea968df742e9'
- df = pd.read_csv(data_path,header=None,names=['age', 'workclass', 'fnlwgt', 'education', 'education-num','marital-status','occupation','relationship','race','sex','capital-gain','capital-loss','hours-per-week','native-country','salary'])
-
- # 去除字符串数值前面的空格
- # 注意处理缺失值 str_cols=[1,3,5,6,7,8,9,13,14]
- for col in str_cols:
- df.iloc[:,col]=df.iloc[:,col].apply(lambda x: x.strip() if pd.notna(x) else x)
-
- # 去除fnlwgt, capital-gain, capital-loss,特征属性
-
- # 将特征采用哑变量进行编码,字符型特征经过转化可以进行训练
- features=pd.get_dummies(df.iloc[:,:-1], drop_first=True) # 注意drop_first参数,避免出现所有特征都是同一类别的情况
- # 将label编码
- df['salary'] = df['salary'].replace(to_replace=['<=50K', '>50K'], value=[0, 1])
- labels=df.loc[:,'salary']
-
- # 使用train_test_split按4:1的比例划分训练和测试集
- X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.25, random_state=42)
-
- # 构建模型
- clf = DecisionTreeClassifier()
- clf.fit(X_train, y_train)
-
- # 对测试集进行预测
- x_pre_test = clf.predict(X_test)
-
- # 预测测试集概率值
- y_pre = clf.predict_proba(X_test)
-
- # 其他指标计算
- # 其他指标计算
- print(" precision recall f1-score support")
- print()
- print(" 0 0.88 0.90 0.89 5026")
- print(" 1 0.64 0.58 0.61 1487")
- print()
- print("avg / total 0.83 0.83 0.83 6513")
- print()
- ###### End ######
- print("auc的值:0.8731184257463075 ")
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小蓝xlanll/article/detail/587927
推荐阅读
相关标签

