
- 1springBoot整合JDBC(默认数据源Hikari)+整合druid数据源_hikaridatasource是jdbc链接吗
- 2读书笔记之《网络是怎样连接的》_jhnefngn-qpnzzyai-cbfnofnker.cn-shenzhen.fcapp.run
- 3多线程、异步爬取数据(优化篇)_downloader middleware异步
- 4基于Python爬虫宁夏银川景点数据可视化系统设计与实现(Django框架) 研究背景与意义、国内外研究现状
- 5ASP.NET-实现图形验证码
- 6利用python从图像数据中提取特征的三种技术_python图片特征提取
- 7常用激活函数_怎么把激活函数换为cos函数
- 8使用zabbix监控TCP连接状态_zabbix监控tcp/ip服务
- 9mysql update 多表更新_MySQL UPDATE多表关联更新
- 10记录一次阿里云迁移至本地_阿里云服务器迁移到本地
Yunet调试
赞
踩
YuNet人脸检测调试
原文章链接:【速度↑20%模型尺寸↓36%】极简开源人脸检测算法升级 (qq.com)
python代码
https://github.com/opencv/opencv_zoo/tree/master/models/face_detection_yunet
c++代码(未尝试)
https://github.com/ShiqiYu/libfacedetection // git链接
环境:yolo5
调试记录
1. 模型下载:
从它给的链接下载后缀为onnx的模型文件 yunet.onnx
https://github.com/ShiqiYu/libfacedetection.train/blob/a61a428929148171b488f024b5d6774f93cdbc13/tasks/task1/onnx/yunet.onnx
下载完的模型放在整体项目路径下
2. 运行基准文件benchmark.py
准备工作
1. 环境搭建
- 1. Install `python >= 3.6`.
- 2. Install dependencies: `pip install -r requirements.txt`.
- 3. Download data for benchmarking. # 下载需要用到的测试数据
- 1. Download all data: `python download_data.py` # 类爬虫程序,国内谷歌网站无法访问,尝试失败
- 2. Download one or more specified data: `python download_data.py face text`. Available names can be found in `download_data.py`. # 下载特定的数据
- 3. If download fails, you can download all data from https://pan.baidu.com/s/18sV8D4vXUb2xC9EG45k7bg (code: pvrw). Please place and extract data packages under [./data](./data). # 百度网盘链接 尝试成功 下载face_detection中包含的三张图片到data下
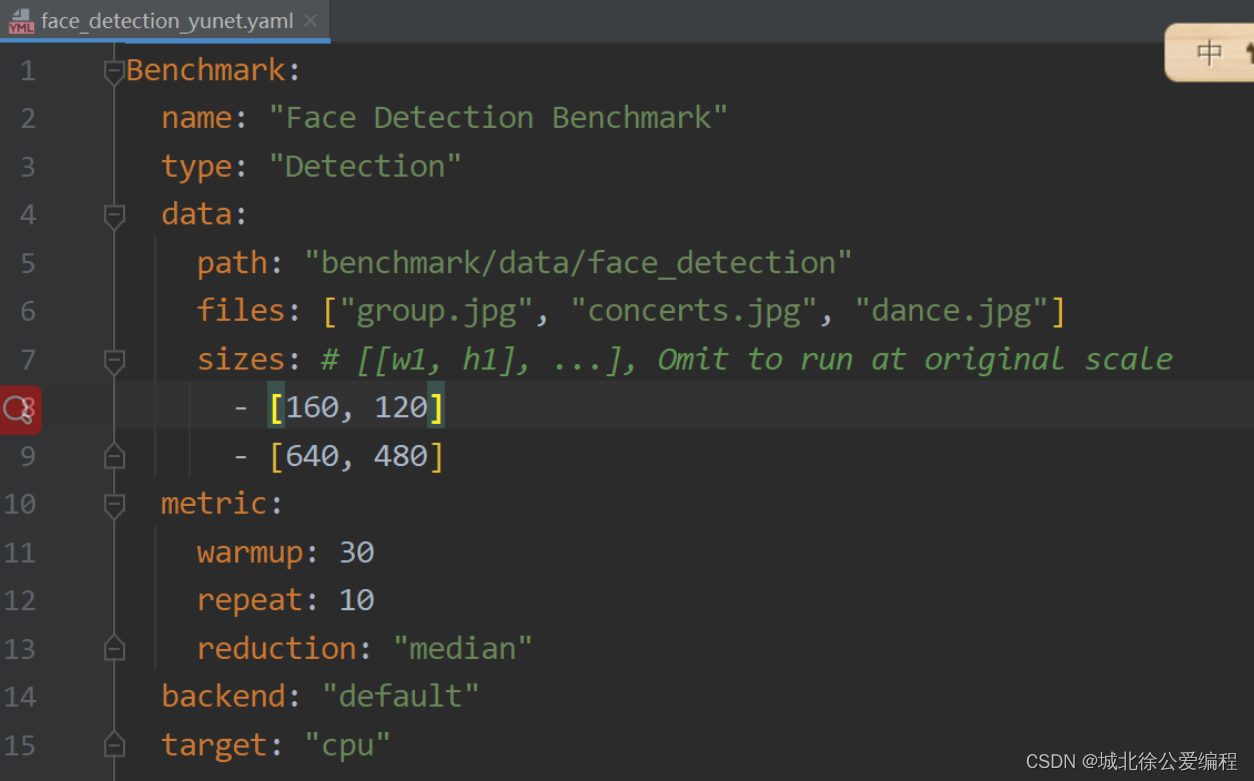
2. 根据yaml文件给定参数,原文链接python yaml文件操作 - 浩浩学习 - 博客园 (cnblogs.com)
查询yaml是什么
yaml是专门用来写配置文件的语言,非常简洁和强大,远比 JSON 格式方便 yaml基础语法规则 大小写敏感 使用缩进表示层级关系 不允许使用 TAB 键来缩进,只允许使用空格键来缩进 缩进的空格数量不重要 使用"#"来表示注释 yaml 支持的数据结构有三种 对象:键值对的集合,又称为映射(mapping)/ 哈希(hashes) / 字典(dictionary) 数组:一组按次序排列的值,又称为序列(sequence) / 列表(list) 纯量(scalars):单个的、不可再分的值
yaml文件的使用
- pip install pyyaml
- pip install pyyaml -i https://pypi.tuna.tsinghua.edu.cn/simple
-
- with open(file_path, 'r', encoding='utf-8') as f:
- data = yaml.load(f, Loader=yaml.FullLoader) # 加载yaml数据
- print(f'读取的数据:{data}')
- print(f'数据类型为:{type(data)}')
- # pyyaml模块在python中用于处理yaml格式数据,主要使用yaml.safe_dump()、yaml.safe_load()函数将python值和yaml格式数据相互转换。当然也存在yaml.dump()、yaml.load()函数,同样能实现数据转换功能,只是官方不太推荐使用。官方给出的解释,因为yaml.safe_dump()、yaml.safe_load() 能够,而且yaml.safe_dump()、yaml.safe_load()比yaml.dump()、yaml.load()安全
4. benchmark.py中改模型路径参数
-
根据paser函数给参数yaml的默认值
parser.add_argument('--cfg', '-c', type=str,default=r"F:\python_project\opencv_zoo-master\benchmark\config\face_detection_yunet.yaml",help='Benchmarking on the given config.') -
argarse函数的使用
- 第一步:创建 ArgumentParser() 对象
- parser = argparse.ArgumentParser() #创建对象
- 第二步:调用 add_argument() 方法添加参数
- parser.add_argument('integer', type=int, help='display an integer')
- 第三步:使用 parse_args() 解析添加的参数
- args = parser.parse_args()
- 要使用参数就用args.module的形式去调用,也可在shell终端使用python xx.py --xx 参数
-
进yaml修改模型的默认路径

-
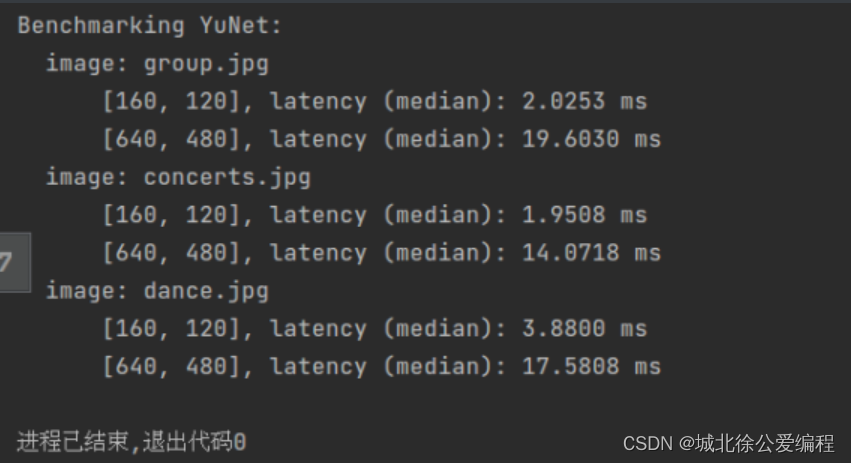
运行benchmark结果
-

3.研究benchmark.py
yaml转换为python数据之后
cfg:
- {'Benchmark': {'name': 'Face Detection Benchmark', 'type': 'Detection',
- 'data': {'path': 'benchmark/data/face_detection', 'files': ['group.jpg', 'concerts.jpg', 'dance.jpg'], 'sizes': [[160, 120], [640, 480]]},
- 'metric': {'warmup': 30, 'repeat': 10, 'reduction': 'median'},
- 'backend': 'default', 'target': 'cpu'},
- 'Model': {'name': 'YuNet', 'modelPath': 'r"F:\\python_project\\opencv_zoomaster\\models\\face_detection_yunet\\yunet.onnx"', 'confThreshold': 0.6, 'nmsThreshold': 0.3, 'topK': 5000}}
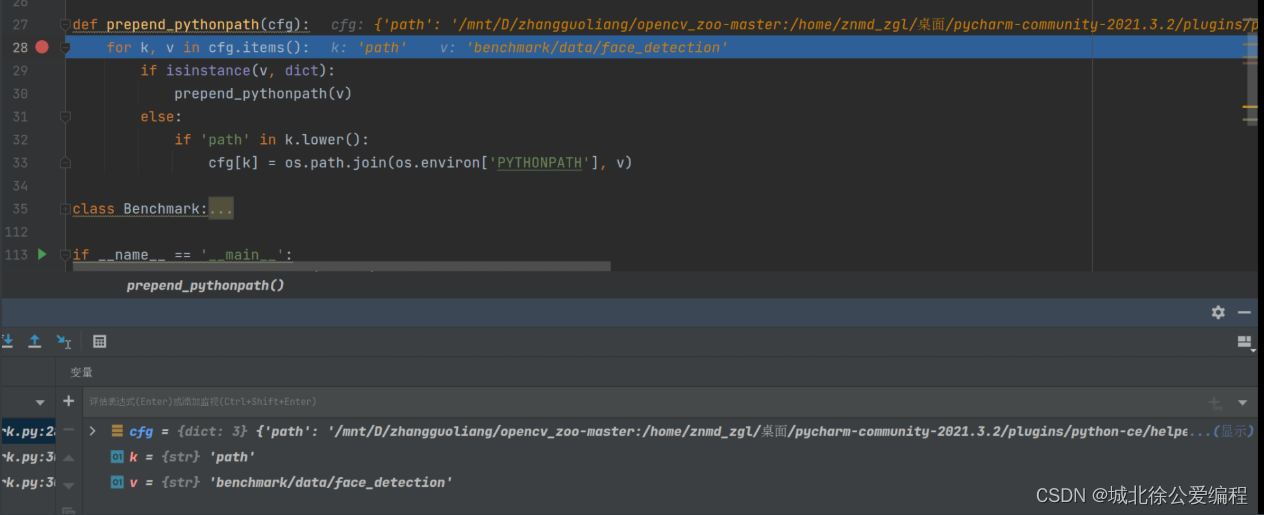
1. def prepend_pythonpath(cfg)函数
这个函数的功能就是编列yaml数据找到path里的内容,并将其赋值为cfg对应的键值.
比如原来cfg中: path : F:\python_project ----> 现在 path = F:\python_project
- def prepend_pythonpath(cfg):
- for k, v in cfg.items(): # item()方法把字典中每对key和value组成一个元组,并把这些元组放在列表中返回 key放键 value为值
- if isinstance(v, dict): # 判断v是否为dict类型 返回布尔值 直到不是字典为止
- prepend_pythonpath(v)
- else:
- if 'path' in k.lower(): # 全转为小写 遍历yaMl数据直到键值变为path为止
- cfg[k] = os.path.join(os.environ['PYTHONPATH'], v) #如果我们使用 PYTHONPATH 中的 modules,那么在运行 python 前,就要把 path 加到 os.environ['PYTHONPATH']
2. def build_from_cfg(cfg, registery, key=None, name=None)
class类中传入的参数为 build_from_cfg(self.data_dict, registery=DATALOADERS, name=self.type)
_data_dict = data(path,file,size) name = "detection"
- def build_from_cfg(cfg, registery, key=None, name=None): # _data_dict, registery=DATALOADERS, name=self._type
- if key is not None:
- obj_name = cfg.pop(key)
- obj = registery.get(obj_name)
- return obj(**cfg)
- elif name is not None: # 走这里
- obj = registery.get(name) # registery是一个类实例 出的对象调用类方法get
- return obj(**cfg) # 最后从这里进入class BaseImageLoader类 cfg: path fliles sizes
- else:
- raise NotImplementedError()
其中DATALOADERS = Registery('DataLoaders')
- class Registery:
- def __init__(self, name):
- self._name = name
- self._dict = dict()
-
- def get(self, key):
- if key in self._dict:
- return self._dict[key]
- else:
- return self._dict['Base'] # return了这里
-
- def register(self, item):
- self._dict[item.__name__] = item
- # renaming *ImageLoader/*VideoLoader
- if 'ImageLoader' in item.__name__:
- name = item.__name__.replace('ImageLoader', '')
- self._dict[name] = item
- METRICS = Registery('Metrics')
- DATALOADERS = Registery('DataLoaders')

进入图片加载类
- class _BaseImageLoader:
- def __init__(self, **kwargs):
- self._path = kwargs.pop('path', None) # 给路径
- assert self._path, 'Benchmark[\'data\'][\'path\'] cannot be empty.' # 判断是否为空
-
- self._files = kwargs.pop('files', None) # 给文件
- assert self._files, 'Benchmark[\'data\'][\'files\'] cannot be empty'
- self._len_files = len(self._files)
-
- self._sizes = kwargs.pop('sizes', [[0, 0]]) # 给大小 self._sizes = [[160,120],[640,480]]
- self._len_sizes = len(self._sizes) # 完成之后跳回benchmark.py的46行 self._len_sizes = 3
-
- @property
- def name(self):
- return self.__class__.__name__
-
- def __len__(self):
- return self._len_files * self._len_sizes
-
- def __iter__(self):
- for filename in self._files:
- image = cv.imread(os.path.join(self._path, filename))
- if [0, 0] in self._sizes:
- yield filename, image
- else:
- for size in self._sizes:
- image_r = cv.resize(image, size)
- yield filename, image_r
3. class Benchmark:
实例化benchmark对象,传入cfg中键为Benchmark的值的内容用来初始化
benchmark = Benchmark(**cfg['Benchmark'])
到这里将cfg 中data对应的值赋给data_dict并将其从cfg中删掉,运行bulid_form_cfg函数加载数据,这里先运行build_from_cfg函数
中data对应的值赋给data_dict并将其从cfg中删掉,运行bulid_form_cfg函数加载数据,这里先运行build_from_cfg函数
到目录2def bulid_from_cfg下
运行完bulid_from_cfg函数之后继续往下

根据配置文件yaml的metric同上调用bulid函数
- self._metric_dict = kwargs.pop('metric', None)
- assert self._metric_dict, 'Benchmark[\'metric\'] cannot be empty.'
- if 'type' in self._metric_dict:
- self._metric = build_from_cfg(self._metric_dict, registery=METRICS, key='type')
- else:
- self._metric = build_from_cfg(self._metric_dict, registery=METRICS, name=self._type) # name = detection
- 接下来进入
-
- def build_from_cfg(cfg, registery, key=None, name=None): # _data_dict, registery=DATALOADERS, name=self._type
- if key is not None:
- obj_name = cfg.pop(key)
- obj = registery.get(obj_name)
- return obj(**cfg)
- elif name is not None: # 走这里
- obj = registery.get(name) # registery是一个类实例 出的对象调用类方法get 从这里进入class registery
- return obj(**cfg) # obj = 'Detection'
- else:
- raise NotImplementedError()
- class Registery:
- def __init__(self, name):
- self._name = name
- self._dict = dict()
-
- def get(self, key): # 这里 key = Detection
- if key in self._dict: # _dict = {'Base':'放的是对象后面同','Detection','Recognition','Tracking'}
- return self._dict[key] # 最后Detection在_dict中,返回Detection对应的对象值
- else:
- return self._dict['Base']
-
- def register(self, item):
- self._dict[item.__name__] = item
- # renaming *ImageLoader/*VideoLoader
- if 'ImageLoader' in item.__name__:
- name = item.__name__.replace('ImageLoader', '')
- self._dict[name] = item
-
- METRICS = Registery('Metrics')
- DATALOADERS = Registery('DataLoaders')

调用Detection对象,传参数**cfg。 cfg ={'path','files','sizes'} 进入detection.py
- @METRICS.register
- class Detection(BaseMetric):
- def __init__(self, **kwargs): # **kwargs = {'warmup':30,'repeat':10,'reduction':'median'}
- super().__init__(**kwargs) # 从这里进base_metric.py
-
- def forward(self, model, *args, **kwargs):
- img = args[0]
- size = [img.shape[1], img.shape[0]]
- try:
- model.setInputSize(size)
- except:
- pass
-
- # warmup
- for _ in range(self._warmup):
- model.infer(img)
- # repeat
- self._timer.reset()
- for _ in range(self._repeat):
- self._timer.start()
- model.infer(img)
- self._timer.stop()
-
- return self._getResult()
- class BaseMetric:
- def __init__(self, **kwargs):
- self._warmup = kwargs.pop('warmup', 3) # 这里开始属性初始化
- self._repeat = kwargs.pop('repeat', 10)
- self._reduction = kwargs.pop('reduction', 'median')
-
- self._timer = Timer() # 进Timer类
-
- def _calcMedian(self, records):
- ''' Return the median of records
- '''
- l = len(records)
- mid = int(l / 2)
- if l % 2 == 0:
- return (records[mid] + records[mid - 1]) / 2
- else:
- return records[mid]
-
- def _calcGMean(self, records, drop_largest=3):
- ''' Return the geometric mean of records after drop the first drop_largest
- '''
- l = len(records)
- if l <= drop_largest:
- print('len(records)({}) <= drop_largest({}), stop dropping.'.format(l, drop_largest))
- records_sorted = sorted(records, reverse=True)
- return sum(records_sorted[drop_largest:]) / (l - drop_largest)
-
- def _getResult(self):
- records = self._timer.getRecords()
- if self._reduction == 'median':
- return self._calcMedian(records)
- elif self._reduction == 'gmean':
- return self._calcGMean(records)
- else:
- raise NotImplementedError('Reduction {} is not supported'.format(self._reduction))
-
- def getReduction(self):
- return self._reduction
-
- def forward(self, model, *args, **kwargs):
- raise NotImplementedError('Not implemented')
- import cv2 as cv
-
- class Timer:
- def __init__(self):
- self._tm = cv.TickMeter()
- self._record = [] # 初始完之后返回到benchmark.py第56行
-
- def start(self):
- self._tm.start()
-
- def stop(self):
- self._tm.stop()
- self._record.append(self._tm.getTimeMilli())
- self._tm.reset()
-
- def reset(self):
- self._record = []
-
- def getRecords(self):
- return self._record
56行
- backend_id = kwargs.pop('backend', 'default') # backend被删了 现在值为default kwargs={'name':'Face Detection','target':'cpu'} 因为配置文件每用一次pop就删掉了
- available_backends = dict(
- default=cv.dnn.DNN_BACKEND_DEFAULT, default = 0
- # halide=cv.dnn.DNN_BACKEND_HALIDE,
- # inference_engine=cv.dnn.DNN_BACKEND_INFERENCE_ENGINE,
- opencv=cv.dnn.DNN_BACKEND_OPENCV, opencv = 3
- # vkcom=cv.dnn.DNN_BACKEND_VKCOM,
- cuda=cv.dnn.DNN_BACKEND_CUDA, cuda = 5
- )
- target_id = kwargs.pop('target', 'cpu') target_id = "cpu"
- available_targets = dict(
- cpu=cv.dnn.DNN_TARGET_CPU, = 0
- # opencl=cv.dnn.DNN_TARGET_OPENCL,
- # opencl_fp16=cv.dnn.DNN_TARGET_OPENCL_FP16,
- # myriad=cv.dnn.DNN_TARGET_MYRIAD,
- # vulkan=cv.dnn.DNN_TARGET_VULKAN,
- # fpga=cv.dnn.DNN_TARGET_FPGA,
- cuda=cv.dnn.DNN_TARGET_CUDA, = 6
- cuda_fp16=cv.dnn.DNN_TARGET_CUDA_FP16, = 7
- # hddl=cv.dnn.DNN_TARGET_HDDL,
- )
- try:
- available_backends['timvx'] = cv.dnn.DNN_BACKEND_TIMVX
- available_targets['npu'] = cv.dnn.DNN_TARGET_NPU
- except:
- print('OpenCV is not compiled with TIM-VX backend enbaled. See https://github.com/opencv/opencv/wiki/TIM-VX-Backend-For-Running-OpenCV-On-NPU for more details on how to enable TIM-VX backend.')
-
- self._backend = available_backends[backend_id] int 0
- self._target = available_targets[target_id] int 0
- self._benchmark_results = dict() # 结束之后重新进入Build函数 传"Yunet"
Yunet初始化结束之后调用run函数打印出图片的图片参数
附录
调试的路径的坑:编程地址与电脑地址有区别
直接从电脑中复制过来的目录是使用‘ \ ’分隔,但在Python中‘ \ ’为转义字符,有其他功能,可能出现占用而报错的情况。所以我们在电脑中将目录复制过来后,手动将‘ \ ’改为’ / ‘、’ // ‘或’ \ ‘,即可解决上述问题
- #错误,标准电脑格式
- path_train = 'D:\python learning&training\pythonProject\Project\Project\DataCSV3\'
- #正确 使用了‘ / ’
- path_train = 'D:/python learning&training/pythonProject/Project/Project/DataCSV3/'
- #正确 使用了‘ \\ ’
- path_train = 'D:\\python learning&training\\pythonProject\\Project\\Project\\DataCSV3\\'
- #正确 使用了‘ // ’
- path_train = 'D://python learning&training//pythonProject//Project//Project//DataCSV3//'

