
- 1【深度学习】实验07 使用TensorFlow完成逻辑回归_tensorflow 逻辑回归
- 2迁移到 OpenAI Python API 库 1.x_openai migrate
- 3linux磁盘IO_linux 磁盘io
- 4springboot整合elasticsearch5.x以及IK分词器做全文检索_springboot elasticsearch 使用ik analyzer查询
- 5Win11配置VPN:L2TP连接尝试失败,因为安全层在初始化与远程计算机的协商时遇到了一个处理错误_win 11 l2tp无法连接
- 6mmcv及mmcv-full安装_mmcv1.5.0安装
- 7Mamba解读(FlashAttention,SSM,LSSL,S4,S5,Mamba)_mamba算法
- 8揭秘艺术的未来:AI绘画自动生成器的魔法
- 9【大数据工具】Spark 伪分布式、分布式集群搭建_spark伪分布式集群搭建
- 10由百鲤跃川主办首届中国企业采购服务产业数字大会于深圳圆满收官
计算机视觉——基于OpenCV和Python进行模板匹配_python opencv 多角度模板匹配
赞
踩
模板匹配
模板匹配是它允许在一幅较大的图像中寻找是否存在一个较小的、预定义的模板图像。这项技术的应用非常广泛,包括但不限于图像识别、目标跟踪和场景理解等。
目标和原理
模板匹配的主要目标是在一幅大图像中定位一个或多个与模板图像相匹配的区域。这个过程就像是用一个“放大镜”在大图像上移动,不断比较模板图像与大图像中相应位置的相似度。通过计算模板图像和大图像中各个位置的像素差异,可以找到与模板图像最为相似的区域。
比较方法
在执行模板匹配时,有多种比较方法可供选择,这些方法决定了如何计算模板图像与大图像之间的相似度。以下是一些常用的比较方法:
-
相关性(Correlation): 这种方法通过计算模板图像和大图像中相应区域的像素值的乘积和来评估相似度。当乘积和最大时,表示两个图像在该位置的匹配度最高。
-
差异(Difference): 与相关性相反,差异方法通过计算模板图像和大图像中相应区域的像素值差的绝对值或平方值来评估相似度。在这种方法中,差异值最小的地方表示匹配度最高。
-
归一化交叉相关(Normalized Cross-Correlation): 这是一种更为健壮的比较方法,它通过将模板图像和大图像的像素值与各自的平均值进行比较来计算相似度。这种方法对于光照变化和图像对比度的变化具有更好的适应性。
-
平方差(Squared Difference): 这种方法计算模板图像和大图像中相应区域的像素值差的平方和。平方差越小,表示匹配度越高。
-
相关系数(Correlation Coefficient): 这是一种基于统计学的方法,它通过计算模板图像和大图像之间的相关系数来评估它们的相似度。相关系数的值介于-1和1之间,值越接近1,表示匹配度越高。
使用OpenCV进行模板匹配
OpenCV提供了cv2.matchTemplate()函数,用于执行模板匹配。
该函数接受以下参数:
- image – 要在其中搜索模板的较大图像。
- template – 在搜索的模板图像。
- method – 要使用的比较方法。有多种可用的比较方法。
然后,函数返回一个包含比较结果的矩阵。矩阵中的每个元素都将具有一个值,指示模板图像与较大图像区域的匹配程度。
# 导入必要的包
import cv2
# 加载主图像和模板图像
image = cv2.imread("examples/1.jpg")
template = cv2.imread("examples/template1.jpg")
# 制作图像的副本
image_copy = image.copy()
# 将图像转换为灰度图像
image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
template_gray = cv2.cvtColor(template, cv2.COLOR_BGR2GRAY)
# 获取模板图像的宽度和高度
template_h, template_w = template.shape[:1]
# 使用归一化交叉相关方法执行模板匹配
result = cv2.matchTemplate(image_gray, template_gray, cv2.TM_CCOEFF_NORMED)
# 找到结果矩阵中最佳匹配的位置
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result)
# 在最佳匹配周围绘制矩形
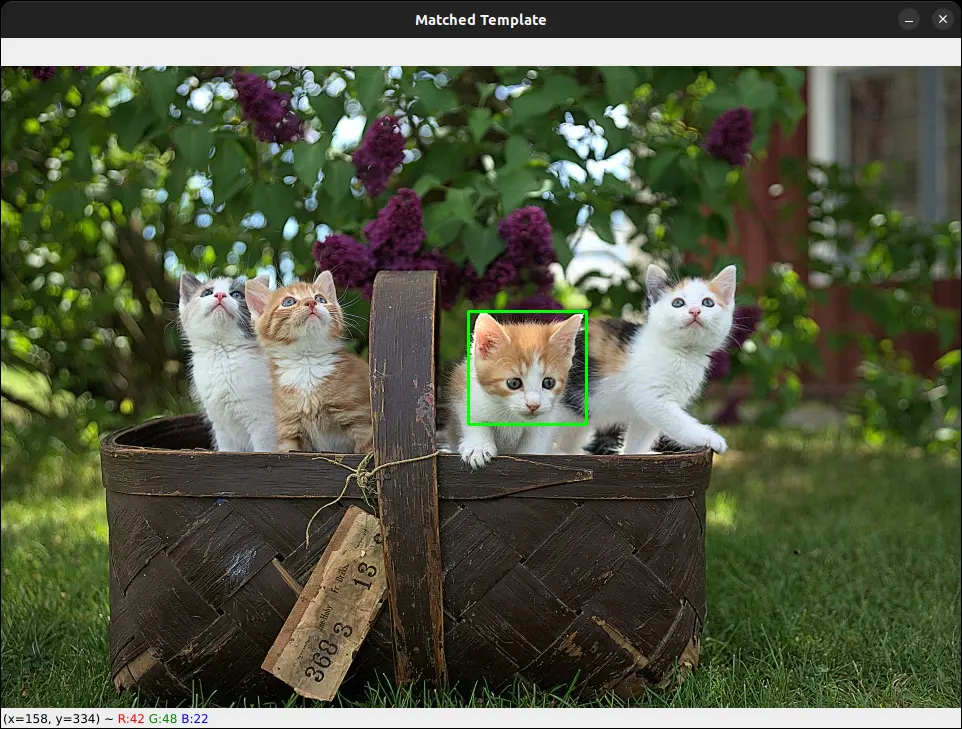
top_left = max_loc
bottom_right = (top_left[0] + template_w, top_left[1] + template_h)
cv2.rectangle(image_copy, top_left, bottom_right, (0, 255, 0), 2)
# 显示图像
cv2.imshow("Image", image)
cv2.imshow("Template", template)
cv2.imshow("Matched Template", image_copy)
cv2.waitKey(0)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33

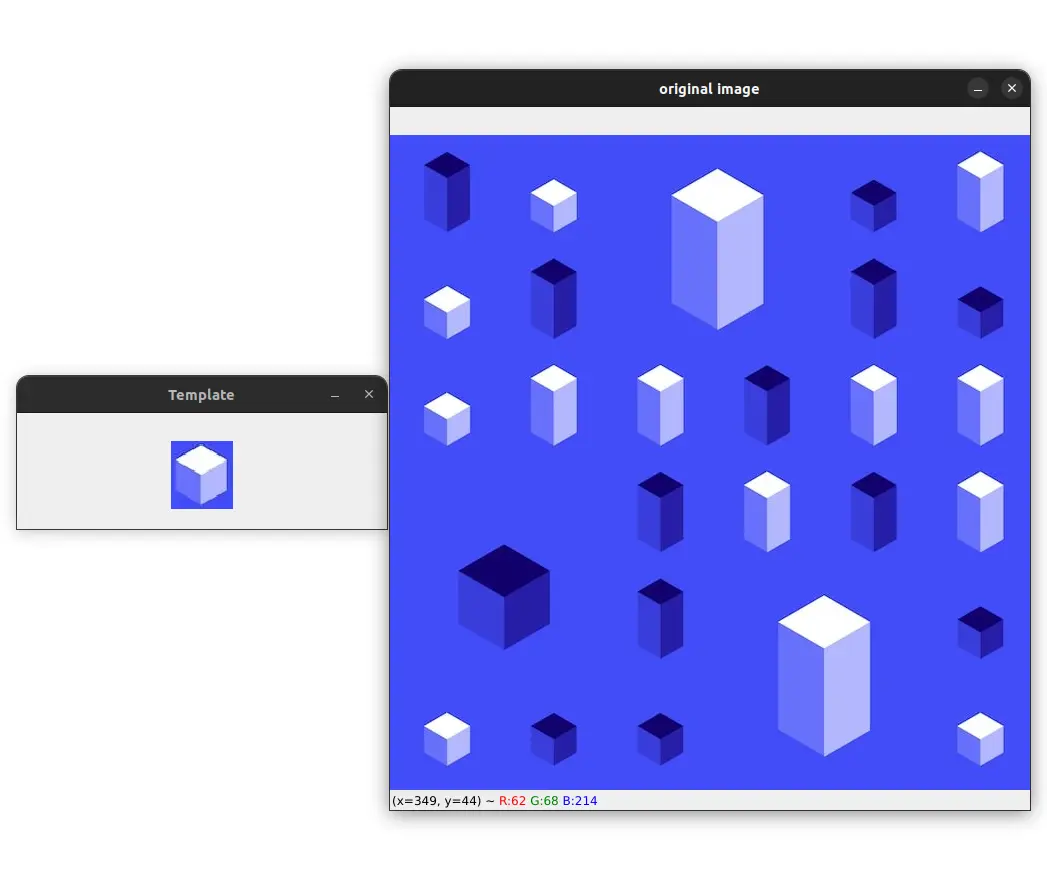
多模板匹配与OpenCV
如果想要在一张图像中检测同一对象的多个实例怎么办?在这种情况下,需要对代码进行一些修改。在之前的代码中,只获取了最佳匹配的位置。可以修改代码,以便获取所有高于某个阈值的匹配位置。
import cv2
import numpy as np
# 设置模板匹配和非极大值抑制阈值
thresh = 0.98
nms_thresh = 0.6
# 加载主图像和模板图像
image = cv2.imread("examples/2.jpg")
template = cv2.imread("examples/template2.jpg")
# 制作图像的副本
image_copy = image.copy()
# 将图像转换为灰度图像
image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
template_gray = cv2.cvtColor(template, cv2.COLOR_BGR2GRAY)
# 获取模板图像的宽度和高度
template_h, template_w = template.shape[:1]
# 使用归一化交叉相关方法执行模板匹配
result = cv2.matchTemplate(image_gray, template_gray, cv2.TM_CCOEFF_NORMED)
# 获取高于阈值的匹配位置的坐标
y_coords, x_coords = np.where(result >= thresh)
print("找到的匹配数量:", len(x_coords))
# 循环遍历坐标并在匹配周围绘制矩形
for x, y in zip(x_coords, y_coords):
cv2.rectangle(image_copy, (x, y), (x + template_w, y + template_h), (0, 255, 0), 2)
# 显示图像
cv2.imshow("Template", template)
cv2.imshow("Multi-Template Matching", image_copy)
cv2.waitKey(0)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37

非极大值抑制在多模板匹配中的应用
非极大值抑制(Non-Maximum Suppression,简称NMS)是目标检测算法中的一个重要步骤,特别是在处理涉及多个模板的情况时,它有助于消除冗余的重叠边界框。OpenCV提供了一个名为cv2.dnn.NMSBoxes()的函数,可以用来执行非极大值抑制。
创建一个边界框列表,使用匹配的坐标,这些匹配的分数高于设定的阈值:
# 创建边界框列表
boxes = np.array([[x, y, x + template_w, y + template_h]
for (x, y) in zip(x_coords, y_coords)])
- 1
- 2
- 3
接下来,对这些边界框应用非极大值抑制:
# 应用非极大值抑制到边界框
indices = cv2.dnn.NMSBoxes(
boxes, result[y_coords, x_coords], thresh, nms_thresh)
- 1
- 2
- 3
cv2.dnn.NMSBoxes()函数接受边界框、分数、阈值和非极大值抑制阈值作为参数。
分数是由模板匹配函数返回的值。只需要获取高于阈值的匹配分数。在上面的代码中,可以通过result[y_coords, x_coords]表达式来做到这一点。
thresh参数在这里不是很重要,因为我们已经过滤掉了低于阈值的匹配。
nms_thresh参数是非极大值抑制阈值。我们已经将其设置为0.6。
函数返回经过非极大值抑制后仍然存在的边界框的索引。例如,回到之前的例子中,这里有8个边界框:
[[347 134 420 206]
[348 134 421 206]
[433 134 506 206]
[347 219 420 291]
[348 219 421 291]
[433 219 506 291]
[348 220 421 292]
[433 220 506 292]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
应用非极大值抑制后,得到这个索引列表:
[2 5 1 4]
- 1
因此,索引2、5、1和4指的是经过非极大值抑制后仍然存在的边界框。可以使用这些索引来保留那些经过非极大值抑制后仍然存在的边界框。
for i in indices:
(x, y, w, h) = boxes[i][0], boxes[i][1], boxes[i][2], boxes[i][3]
cv2.rectangle(image, (x, y), (w, h), (0, 255, 0), 2)
- 1
- 2
- 3
然后在主图像上绘制边界框。结果将与之前的相似,但如果仔细观察,会发现边界框的厚度不同。这是因为使用非极大值抑制去除了重复的边界框。

