
- 1国产系统软件网站_国产app网站
- 2安装docker时,遇到Loaded plugins...怎么办
- 3解决Could not install packages due to an EnvironmentError: [WinError 5] 拒绝访问。: ‘f:\program files\p
- 4Docker本地部署Drupal内容管理框架并实现公网远程访问_本地管理框架
- 5OSI与TCP/IP各层的结构与功能及协议_tcp/ip和osi分层模型每层对应的协议
- 6SpringBoot全局异常处理 | Java
- 7产品经理之Axure的元件库使用&详细案例_axure 移动端元件库
- 8【干货分享】前端面试知识点锦集01(HTML篇)——附答案_从下列选中中选出不同的一个?a
- 9Python自动操作 GUI 神器——PyAutoGUI_python判断鼠标在主屏还是副屏
- 10行人重识别(4)——行人重识别(基于视频)综述
Deep Learning with OpenCV DNN Module介绍
赞
踩
Deep Learning with OpenCV DNN Module介绍
1. 源由
看了一些资料和数据,感觉他讲的非常好,也顺便整理记录下。
但是有几点我觉得应该提前说明下:
- 很多事情都不是绝对的,看到的资料也未必就是一成不变的;随着时间的推移,技术的进步,很多情况都会发生变化;
- 虽然有些资料说OpenCV对Intel CPU做了各种优化,但是现在就笔者手上就有Jetson Orin Nano的板子,从GPU运算的角度,一定不会比CPU差到哪里去。从逻辑的角度,GPU更适合行列式运算;
- 科学依据是讲究的量化对比数据,因此,快很多,好不少,这些概念都太空洞,有很多主管色彩;
- 个人观点:边缘计算或者说大量的现实应用实际上是Inference,而非training;因此,OpenCV着重使用模型进行Inference是一个不错的idea;
多说一些个人的理解:我想的一个问题是“我们人类是学习的时间多呢?还是推理的时间多呢?”这仅仅是一个问题,其实人的思维层面可能在不断的学习。
如果我们简单的思考或者抽象成两种模式:
- A:先学习,形成固有的知识体系,形成记忆;然后应用知识体系(记忆)进行应用;
- B:先学习,形成基本的概念和逻辑;然后应用逻辑概念,应用知识,且不断迭代纠偏;再进一步应用迭代;
这里有一个非常有意思的事情就是A非常简单,而且非常适合我们这里的OpenCV深度神经网络应用。
而B其实个人认为更加适合与复杂场景,更加具备人工智能的情景。换句话说,A是一种基于非全面归纳的固定逻辑的预知推演;而B是一种基于非全面归纳的可变逻辑的预知推演;
A具有先天性;B在先天性的基础上,受环境影响。这里也不得不提一下《一种部件生命期监测方法》,是一种多因素的问题分析的方法和手段,是一种B的预测方案。
2. 为什么/什么是OpenCV DNN Module?
OpenCV是最好的计算机视觉库之一。自OpenCV 3.3版本以来,支持从不同框架加载不同模型,使用这些模型可以执行多种深度学习功能。
OpenCV的DNN模块支持对图像和视频进行深度学习推断,但不支持微调和训练。然而,运用深度学习推断的功能可以让任何初学者开始深度学习计算机视觉,是实践接触深度神经网络的理想起点。
OpenCV的DNN模块最大的优点之一是针对英特尔处理器进行了高度优化。
在实时视频上运行目标检测和图像分割应用时,可以获得很好的帧率。当使用特定框架预训练的模型时,通常使用DNN模块时可以获得更高的帧率。
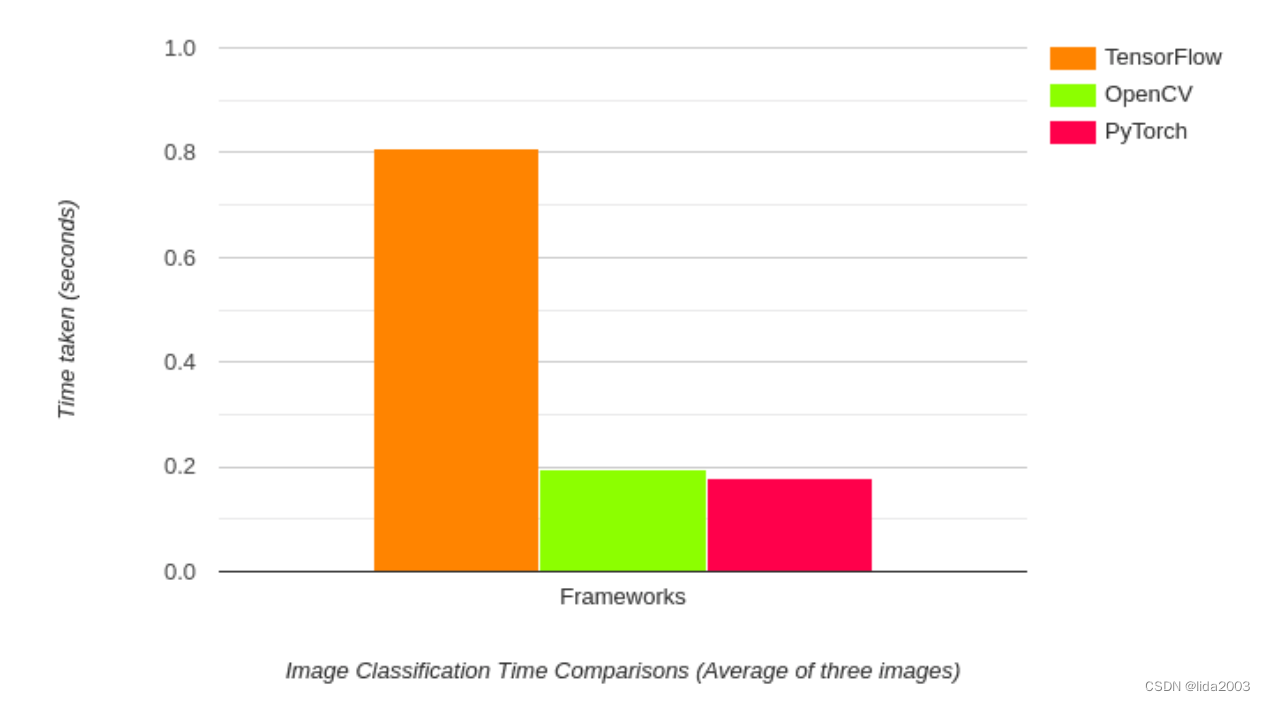
以上结果是DenseNet121模型的推断时间。令人惊讶的是,OpenCV比TensorFlow的原始实现要快得多,而与PyTorch相比略有落后。事实上,TensorFlow的推断时间接近1秒,而OpenCV只需不到200毫秒。
以上基准测试是基于PyTorch 1.8.0、OpenCV 4.5.1和TensorFlow 2.4。所有测试都在拥有英特尔至强处理器2.3GHz的Google Colab上进行。
即使在目标检测的情况下也是如此。
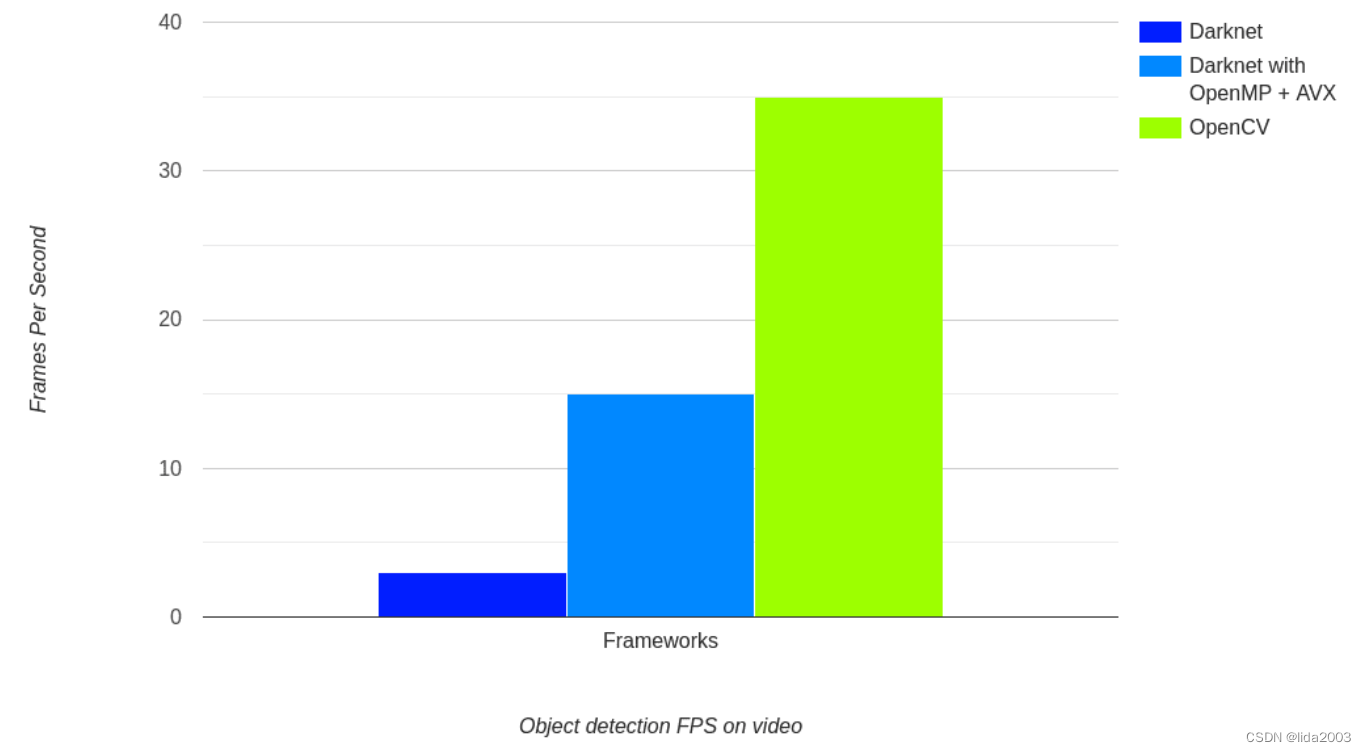
以上图表显示了在原始Darknet框架和OpenCV上使用Tiny YOLOv4进行视频FPS测试的结果。基准测试是在具有2.6GHz时钟的英特尔第八代i7笔记本电脑CPU上进行的。我们可以看到,在相同的视频中:
- OpenCV的DNN模块以35 FPS运行
- 使用OpenMP和AVX编译的Darknet以15 FPS运行
- 没有使用OpenMP和AVX的Darknet Tiny YOLOv4速度最慢,只有3 FPS
以上图表展示了在使用CPU时,OpenCV DNN模块的实际用途和强大性。由于其快速的推断时间,即使在CPU上,它也可以作为在计算能力有限的边缘设备上的优秀部署工具。
基于ARM处理器的树莓派作为边缘设备是最好的例子之一,以下图表是对此的良好证明。
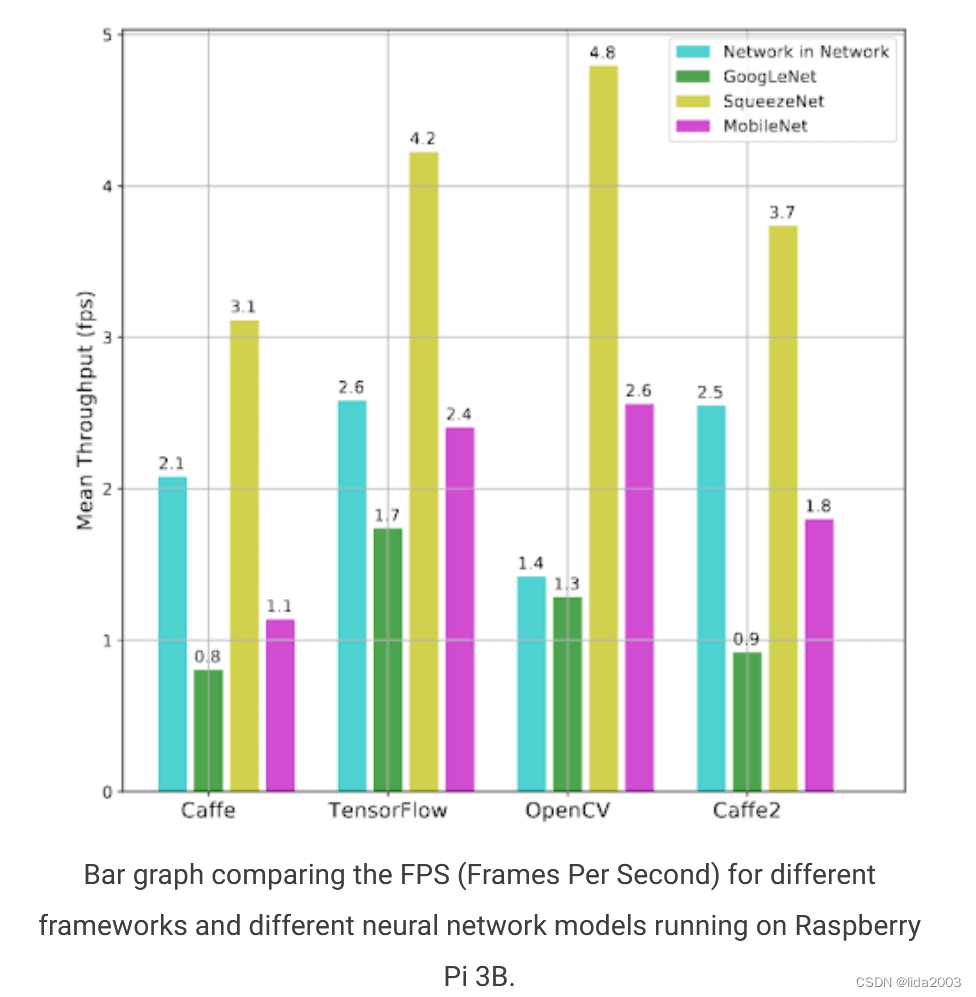 以上图表显示了在树莓派3B上运行不同框架和模型的FPS。结果非常令人印象深刻。
以上图表显示了在树莓派3B上运行不同框架和模型的FPS。结果非常令人印象深刻。
- 对于SqueezeNet和MobileNet模型,OpenCV在FPS方面超过了所有其他框架
- 对于GoogLeNet,OpenCV排名第二,TensorFlow速度最快
- 对于Network in Network模型,OpenCV在树莓派上的FPS最慢
以上几个图表展示了经过优化的OpenCV在神经网络推断方面有多快。这些数据为选择深入了解OpenCV DNN模块提供了充分的理由。
2.1 支持的不同深度学习功能
以下是OpenCV DNN模块支持的功能列表:
- 图像分类:为图像分配标签或类别。
- 目标检测:定位并分类图像中的对象。
- 图像分割:将图像分割成片段以简化其表示。
- 文本检测和识别:识别并解释图像中的文本。
- 姿态估计:估计图像中对象或人的姿态或方向。
- 深度估计:估计物体与摄像机之间的距离以创建深度图。
- 人脸和人物验证与检测:识别和验证个体或检测图像中的人脸。
- 人员识别:人员重新识别,即跨不同摄像机视图或时间识别个体。
这些功能涵盖了深度学习和计算机视觉中的各种任务,使OpenCV DNN模块成为多种应用的通用工具。
注:要了解更多关于每个功能的详细信息,请访问Deep Learning in OpenCV Wiki页面。
2.2 支持的不同模型
为了支持上面讨论的所有应用程序,需要大量预训练模型。此外,还有许多最先进的模型可供选择。以下表格列出了一些根据不同深度学习应用程序的模型。
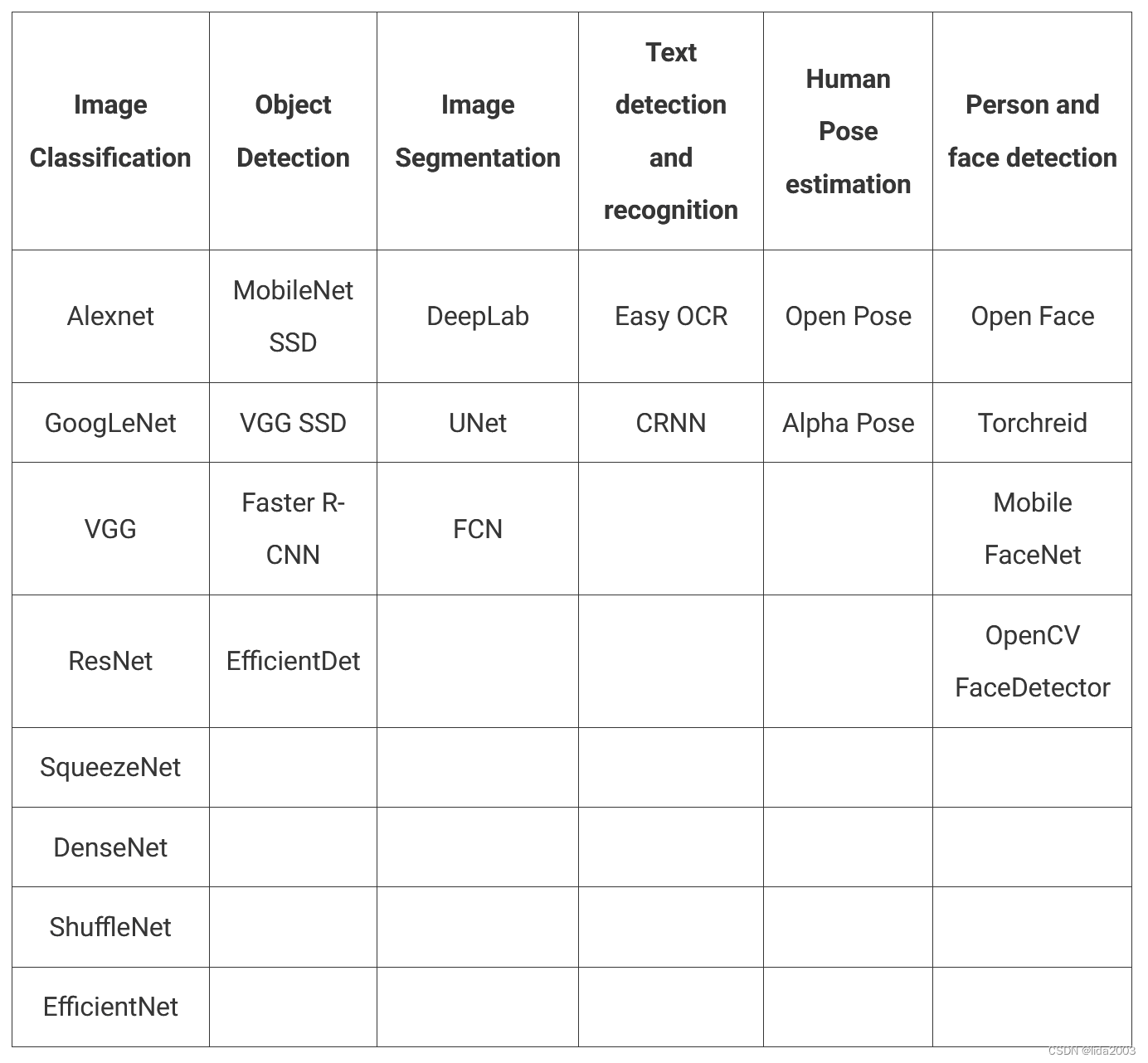 以上提到的模型并不是详尽无遗的。实际上还存在许多其他模型。正如前面提到的,要在一篇博客中完整列出或详细讨论每个模型几乎是不可能的。以上列表给了很好的举例和概要,即DNN模块在探索计算机视觉中的深度学习方面是多么实用。
以上提到的模型并不是详尽无遗的。实际上还存在许多其他模型。正如前面提到的,要在一篇博客中完整列出或详细讨论每个模型几乎是不可能的。以上列表给了很好的举例和概要,即DNN模块在探索计算机视觉中的深度学习方面是多么实用。
2.3 支持的不同框架
看着上面列出的所有模型,一个问题冒了出来:“这些模型都由单一框架支持吗?”实际上,并不是。
OpenCV的DNN模块支持许多流行的深度学习框架:
- Caffe
要使用OpenCV DNN加载预训练的Caffe模型,我们需要两样东西。一是包含预训练权重的model.caffemodel文件。另一个是模型架构文件,其扩展名为.prototxt。它类似于一个普通的文本文件,具有类似JSON的结构,包含所有神经网络层的定义。要了解此文件的具体结构,请访问此链接。
- TensorFlow
要加载预训练的TensorFlow模型,我们同样需要两个文件。一个是模型权重文件,另一个是Protobuf文本文件,其中包含模型的配置信息。权重文件的扩展名为.pb,它是一个包含所有预训练权重的Protobuf文件。如果您之前使用过TensorFlow,您会知道.pb文件是在保存模型并冻结权重后得到的模型检查点。模型配置保存在Protobuf文本文件中,其扩展名为.pbtxt。
注意:在较新版本的TensorFlow中,模型权重文件可能不是.pb格式。如果您尝试使用自己保存的模型,该模型可能是.ckpt或.h5格式。在这种情况下,需要执行一些中间步骤才能使模型能够与OpenCV DNN模块一起使用。在这种情况下,将模型转换为ONNX格式,然后再转换为.pb格式是确保一切正常运作的最佳方法。
- Torch和PyTorch
要加载Torch模型文件,我们需要包含预训练权重的文件。通常,这个文件的扩展名为.t7或.net。但随着最新的PyTorch模型具有.pth扩展名,首先将其转换为ONNX是继续操作的最佳方式。转换为ONNX后,您可以直接加载它们,因为OpenCV DNN支持ONNX模型。
- Darknet
OpenCV DNN模块还支持著名的Darknet框架。如果您使用过Darknet框架的官方YOLO模型,可能会认出它。
通常,要加载Darknet模型,我们需要一个具有.weights扩展名的模型权重文件。Darknet模型的网络配置文件始终是一个.cfg文件。
3. 如何使用OpenCV DNN模块
3.1 使用从Keras和PyTorch等不同框架转换为ONNX格式的模型
通常,使用PyTorch或TensorFlow等框架训练的模型不能直接与OpenCV DNN模块一起使用。在这些情况下,通常我们将模型转换为ONNX格式(Open Neural Network Exchange),然后可以直接使用它,甚至将其转换为其他框架(如TensorFlow或PyTorch)支持的格式。
要加载一个ONNX模型,我们需要OpenCV DNN模块的.onnx权重文件。
注:请访问官方OpenCV文档,了解不同框架、它们的权重文件以及配置文件的相关信息。上面的列表涵盖了所有著名的深度学习框架。要完整了解OpenCV DNN模块支持的所有框架和模型,请访问官方的Wiki页面。
3.2 使用OpenCV DNN模块的基本步骤
用OpenCV DNN模块的方法取决于您要执行的特定任务,例如图像分类、目标检测或实例分割。一般来说,您需要执行以下步骤:
- 加载模型: 使用OpenCV的cv2.dnn.readNet()函数加载预训练的深度学习模型。您需要提供模型的配置文件和权重文件的路径。
net = cv2.dnn.readNet(model_path, config_path)
- 1
- 准备输入: 将您的输入图像转换为模型所需的格式。这可能涉及对图像进行调整大小、归一化等操作。
blob = cv2.dnn.blobFromImage(image, scalefactor=1.0, size=(width, height), mean=(0, 0, 0), swapRB=False, crop=False)
- 1
- 执行推理: 将预处理的输入图像传递给模型,并使用forward()方法执行推理。
net.setInput(blob)
outputs = net.forward()
- 1
- 2
- 处理输出: 根据您的任务,处理模型的输出。例如,对于目标检测,您可能需要解析边界框并绘制它们在图像上。
for detection in outputs[0, 0]:
confidence = detection[2]
if confidence > confidence_threshold:
# 解析检测结果并进行相应处理
- 1
- 2
- 3
- 4
以上只是一个基本的框架,实际的使用取决于您的具体任务和模型。您可能需要详细了解特定任务的模型的输入和输出格式,以及如何解析和处理模型的输出。
注:具体例子,可参考:ubuntu22.04@laptop OpenCV Get Started: 015_deep_learning_with_opencv_dnn_module。
4. 参考资料
【1】ubuntu22.04@laptop OpenCV Get Started
【2】ubuntu22.04@laptop OpenCV安装
【3】ubuntu22.04@laptop OpenCV定制化安装

